

[Python][教學] 網路爬蟲(crawler)實務(上)--網頁元件解析
今年部落格最受歡迎文章:[Python] 現學現賣之網路爬蟲(Crawler)--以抓本BLOG為例是我剛學python時寫的程式,內容其實也都是照著老師的課程講義來做,很多細節也是矇懞懂懂.至今過了半年,爬網的經驗也多了一點,比較有內容可以跟大家分享.爬網有很多種用途,對比起搜尋引擎的全頁抓取,更多時候是抓取特定網站的特定內容,這時候除了爬蟲程式本身之外,對於網站欄位的解析更為重要.
今年部落格最受歡迎文章:[Python] 現學現賣之網路爬蟲(Crawler)--以抓本BLOG為例是我剛學python時寫的程式,內容其實也都是照著老師的課程講義來做,很多細節也是矇懞懂懂.至今過了半年,爬網的經驗也多了一點,比較有內容可以跟大家分享.爬網有很多種用途,對比起搜尋引擎的全頁抓取,更多時候是抓取特定網站的特定內容,這時候除了爬蟲程式本身之外,對於網站欄位的解析更為重要.
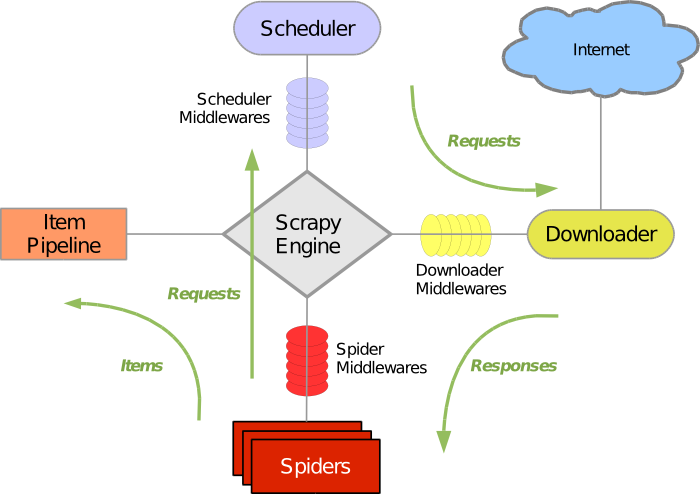
Scrapy是python上很受歡迎的爬網框架,官方網站為:http://doc.scrapy.org/en/latest/index.html.介紹Scrapy的網站很多,官網自己就寫得很清楚,一些中文化的資料可參考像是http://www.addbook.cn/book/scrapy中文手册等資料.今天主要介紹的是爬網之後的動作.爬網並不是單純爬文而已,而是為了提供之後進一步的分析,所以資料都必須儲存下來,儲存的方式有很多種,可以單純是個file,再由分析軟體來處理資料,或是把資料放在資料庫中,做進一步的分析.
