
.png)
Visualization
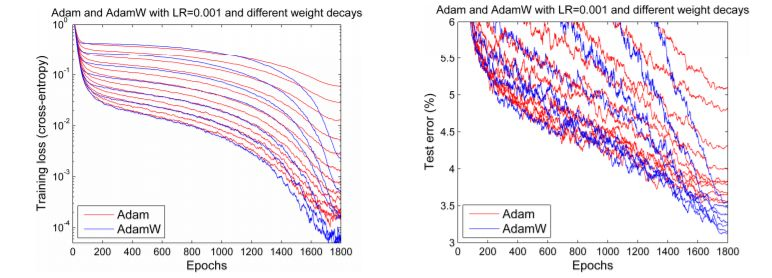
當前訓練神經網絡最快的方式:AdamW優化算法+超級收斂
摘要: 最優化方法一直是機器學習中非常重要的部分,也是學習過程的核心算法。而 Adam 自 14 年提出以來就受到廣泛關注,目前該論文的引用量已經達到了 10047。不過自去年以來,很多研究者發現 Adam 優化算法的收斂性得不到保證,ICLR 2017 的最佳論文也重點關注它的收斂性。在本文中,作者發現大多數深度學習庫的 Adam 實現都有一些問題,並在 fastai 庫中實現了一種新型 AdamW 算法。根據一些實驗,作者表示該算法是目前訓練神經網絡最快的方式。
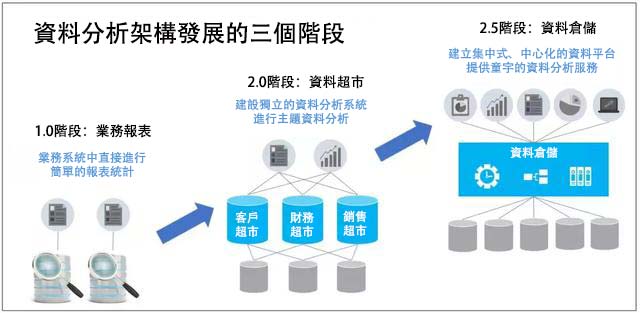
企業如何選擇資料分析架構?談談3種架構的利弊
摘要: 在之前的文章《講透大數據,我只需要一頓飯》里,用做飯這件大家身邊的事情來介紹了大數據及資料分析工程,應該能夠讓大家對資料分析這件看上去很專業的行業有了一定的認識,很高興的是文章也得到了很多資料圈專業人士的共鳴和互動。 這篇文章我們會順著之前的思路,稍微深入一點,聊聊資料分析架構。
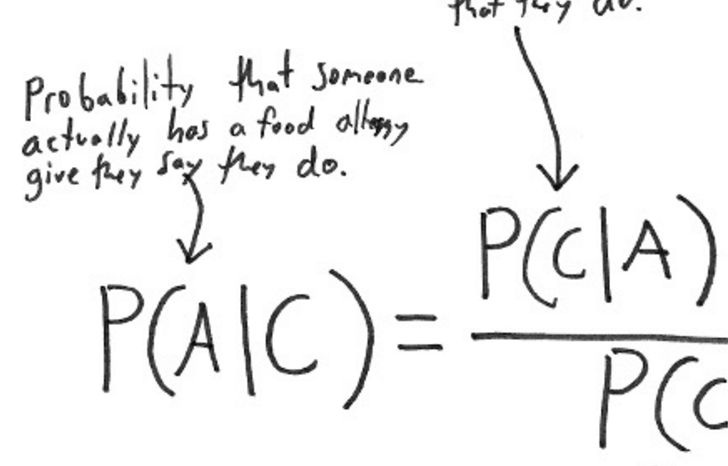
Bayesian Inference, an interactive visualization
摘要: The visualization shows a Bayesian two-sample t test, for simplicity the variance is assumed to be known. It illustrates both Bayesian estimation via the posterior distribution for the effect, and Bayesian hypothesis testing via Bayes factor. The frequentist p-value is also shown. The null hypothesis, H0 is that the effect δ = 0, and the alternative H1: δ ≠ 0, just like a two-tailed t test. You can use the sliders to vary the observed effect (Cohen's d), sample size (n per group) and the prior on δ.

當前機器學習成果真的可靠嗎?UCB & MIT 新研究質疑測試
摘要: 近日,UCB和MIT研究者發佈的一篇名爲《Do CIFAR-10 Classifiers Generalize to CIFAR-10?》的新論文提出了學界一個尖銳的問題:包括CIFAR10在內的知名基準測試集,都存在驗證集過擬合問題。
從圖像處理到語音識別,25款數據科學家必知的深度學習開放數據集
摘要: 深度學習(或生活中大部分領域)的關鍵在於實踐。你需要練習解決各種問題,包括圖像處理、語音識別等。每個問題都有其獨特的細微差別和解決方法。

金融大數據運用與隱私權保護
摘要: 金融大數據的運用有助於提高金融監管能力,重塑金融監管的方式。金融先進技術可以讓金融監管發揮更大的效力。先進的信息系統可以及時檢測金融市場與企業的動態大數據。

一篇深度強化學習勸退文
摘要: 今天在學校又雙提到了 Deep Reinforcement Learning That Matters 這篇打響 DRL(Deep Reinforcement Learning, 深度強化學習)勸退第一槍的文章後,回來以後久違刷了一下推特,看到了這篇爆文 Deep Reinforcement Learning Doesn't Work Yet,或可直譯爲深度強化學習還玩不轉或意譯爲深度強化學習不能即插即玩。

DISTRIBUTED AND REAL-TIME MACHINE LEARNING FOR FINANCIAL DATA ANALYSIS (WP1)
Big data has both high volume and high velocity – one way this manifests is as silos of in-situ data representing departments in banks that are very difficult to move and integrate to obtain a single coherent customer view. Further, the ability to perform data analytics – dynamically and in near real-time – of rapidly changing customer and market data is increasingly critical for competitiveness. By considering the distributed nature of financial data storage and the velocity of financial markets, the objective of this RP is to develop distributed and real-time machine learning methods to identify decentralised and dynamic models for financial analysis, prediction, and risk management.
This project will develop (i) methods to identify cross-effects between different data resources, regions, sectors, and markets, (ii) distributed versions of methods to identify decentralised models that include individual local model components learned from local resources and cross-impact model components learned from data resources in other regions/sectors/markets, and (iii) real-time learning methods to update decentralised models and address financial market velocity.
Based on the distributed and cloud computing infrastructure, this approach should address the weakness of existing data-centralised and off-line machine learning methods, which fail to consider the cost of data transportation, storage, and fast timevarying characteristics of financial markets. The originality of this approach is its dynamic integration, by distributed and real-time mining, to maximise the effectiveness and efficiency of big data analysis.
Early Stage Resercher working on the project: Sergio Garcia Vega
Supervisor: Professor John Keane, University of Manchester / john.keane(at)manchester.ac.uk
轉貼自: Finance BigData.eu

用Python 連接MySQL 的幾種方式
摘要:儘管很多NoSQL 數據庫近幾年大放異彩,但是像MySQL 這樣的關係型數據庫依然是互聯網的主流數據庫之一,每個學Python 的都有必要學好一門數據庫,不管你是做數據分析,還是網絡爬蟲,Web 開發、亦或是機器學習,你都離不開要和數據庫打交道,而MySQL 又是最流行的一種數據庫,這篇文章介紹Python 操作MySQL 的幾種方式,你可以在實際開發過程中根據實際情況合理選擇。

2018年人工智能和機器學習路在何方?聽聽美國公司怎麼做
摘要: 本文為美國著名數據分析網站DZone分析師Tom Smith與Exaptive的副總裁Matt Coatney的專訪對話,對人工智能和機器學習的未來做了深度的探討.Exaptive是一家美國俄克拉荷馬州以提供大數據分析產品及服務為主的初創企業。
YOU MAY BE INTERESTED
