
摘要: 近年來,伴隨移動互聯網、虛擬現實等技術的飛速發展,銀行服務模式日趨多樣化。在客戶享受靈活便捷服務的同時,銀行欺詐風險呈現出更加隱蔽、專業的特點,發展出更多的作案手法和表現形式。傳統欺詐檢測通常依賴專家...
銀行智能欺詐風險預測模型研究
近年來,伴隨移動互聯網、虛擬現實等技術的飛速發展,銀行服務模式日趨多樣化。在客戶享受靈活便捷服務的同時,銀行欺詐風險呈現出更加隱蔽、專業的特點,發展出更多的作案手法和表現形式。傳統欺詐檢測通常依賴專家規則、黑名單庫等方法,已經不能適應新的欺詐挑戰。銀行亟需研究並應用先進的機器學習算法,以數據價值為驅動建立智能化的風險預測模型,以此作為欺詐風險防範的強力手段。
一、銀行反欺詐發展趨勢
國內外銀行在傳統反欺詐管理中主要依賴專家經驗,通過人工方式製定檢測規則,當申請或交易信息與反欺詐規則匹配後即執行相應的業務策略。這種管理模式得出的反欺詐規則存在一定的局限性,不能枚舉所有業務場景,無法對各類欺詐行為進行全面覆蓋。與此對應,欺詐者會針對性的對已有規則進行迴避,導致專家規則處於被動調整的位置,無法跟上欺詐手段的更新換代[1, 2]。另外,當專家規則積累達到一定數量後誤報率通常會比較高,能夠影響到實際風險決策制定和實際業務開展。
機器學習是一種重要的金融科技創新手段,近年來在國內外金融機構和金融科技企業中被嘗試應用到風險防範、反欺詐等領域。例如花旗銀行、美國銀行、匯豐銀行等機構廣泛應用邏輯回歸、神經網絡等技術以提升欺詐識別能力;京東金融與ZestFinance組建的合資公司以數據挖掘建模為核心競爭力,在反欺詐領域深入應用機器學習技術以發揮大數據價值。機器學習是一種研究機器獲取新知識和新技能,並識別現有知識的方法[3];通常針對大規模數據集進行全方位綜合考量,挖掘深層次業務場景特徵進而建立監督、無監督等類型的學習模型,在大量應用中模型的準確性、穩定性也得到了充分驗證[4]。
為此,我們針對信用卡申請審批這一典型業務場景,應用機器學習技術進行欺詐風險管理並設計數據產品對異常客戶進行監控預警。區別於將機器學習技術應用到單一反欺詐規則制定的典型做法,我們嘗試從整體視角對欺詐風險進行評估,實現精準量化預測並以此作為應對欺詐風險的強有力手段。建模思路及方法具有一定的可遷移性,可以被廣泛應用到銀行風險防範、反欺詐等業務領域。
二、“會思考”的風控模型
在應用大數據支持業務發展轉型的過程中,我們提出構建增強智能(Augumented Intelligence)系統[5]的創新思路。一個務實的增強智能係統包括客戶畫像、數據挖掘模型和決策引擎三個組成部分。數據挖掘模型是智能化的核心,客戶畫像為建模過程持續提供特徵輸入,決策引擎將模型輸出成果轉換為實際業務行動。增強智能係統的一個重要目標是提升傳統業務流程的自動化水平,過程中的大數據能力主要體現在三個方面,也就是下圖中的三個組成部分:更好的客戶認知、更智能化的算法、更快速的決策支持。

圖1:增強智能係統組成模塊
數據挖掘模型發揮動力引擎作用,吸收學術界和產業界先進機器學習知識成果並應用於銀行實踐。客戶畫像重點體現大數據背景下的客戶多維度刻畫,在靜態信息和交易行為信息之外可以補充社交網絡維度特徵信息。伴隨大數據的持續採集、生產和交換,客戶畫像能夠進一步補充情緒屬性、價值觀屬性乃至道德屬性等信息,為數據挖掘建模提供源源不斷的能源輸入。決策引擎能夠面對業務場景進行快速響應,通過可視化等手段提供自助式業務分析能力,促進數據價值轉化為業務行動。
踐行上述思路,我們結合傳統風險管控和社交網絡分析技術,加工基礎維度信息和社交維度信息特徵指標組成反欺詐客戶畫像,並應用隨機森林等分佈式機器學習算法建立欺詐風險預測模型。不同於傳統風控模型以年為單位的更新優化週期,智能化預測模型每天都能夠進行“思考”,通過更新網絡關係並重新訓練模型確定的欺詐預測思維模式。模型在研發和使用的過程中靈活運用機器學習和社交網絡分析技術,催生新型數據產品的開發與應用從而帶動傳統業務流程的優化。
三、模型構建與結果分析
以銀行信用卡申請反欺詐為應用場景,詳細描述社交網絡構建、特徵處理、算法實現、運行結果分析等階段過程。
1、結合社交視角構造客戶特徵信息
社交網絡分析是融合多學科理論和方法,為理解各種社交關係的形成、行為特點分析以及信息傳播的規律提供的一種可計算的分析方法[6]。社交網絡分析方法旨在建立一個網絡與真實世界的實體與關係映射,在銀行應用中的典型實體包括客戶、賬戶、員工等。社交網絡分析通常關注靜態和動態兩個層面的網絡特徵,靜態特徵包括提取網絡指標、對網絡特徵刻畫、識別網絡群組等;動態特徵主要包括描述網絡如何隨時間推移進行擴散、如何影響其他節點等。
分析信用卡進件審批數據,確定數據中包含四種角色,分別是申請人、申請人親屬、聯繫人和推廣人。在建模實施過程中將申請人角色作為社交網絡的關鍵節點,把申請人、申請人親屬、聯繫人及推廣人這四種角色的移動電話、家庭電話、辦公電話的相同作為關係類型。建模過程中構建的社交網絡包括780萬節點,2.33億條關係。
在構建完成社交網絡後,設計併計算一二階度、一二階欺詐數、一二階欺詐佔比、最短路徑等網絡指標。從網絡視角衡量欺詐風險的傳播,度反映節點關聯好友數量,最短路徑反映網絡中節點間親密程度。此外,建模中的客戶基礎信息包括申請人年齡、手機號、單位電話、電子郵箱、學歷、年收入、職位等,針對這些信息需要進行結構化分解、離散化、頻度計算等數據預處理操作,共同構建特徵以用於後續模型的訓練和驗證。
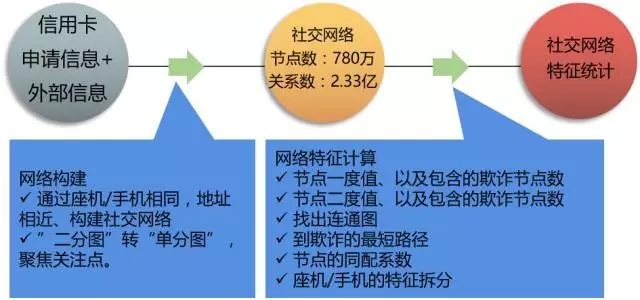
圖2:反欺詐模型特徵構造過程
2、建模方案設計
對進行特徵工程化處理的數據進行拆分,設置三組建模數據集,分別是基礎信息的數據集(base)、社交信息的數據集(social),以及組合在一起的數據集(combine) 。建模過程中採用3折交叉驗證的方式完成欺詐風險預測模型建立和訓練,並比較多組模型輸出的計算結果。
算法選擇方面,分別選擇邏輯回歸(LogisticsRegression, LR),隨機森林[7](Random Forests, RF)和深度學習 [8](Deep Learning, DL)。邏輯回歸是銀行風控領域的經典算法,以此作為模型結果的標杆參考。隨機森林是一種集成學習算法,利用多棵決策樹對樣本進行訓練並預測;通常單棵樹性能表現較弱,但進行組合之後能夠提供較好的分類性能,同時算法穩定性較好。深度學習(DL)模型是包含多隱層的多層感知器系統,通過應用綜合複雜結構和多重非線性變換構成的多個處理層及對數據進行高層抽象的一系列算法,建立具有數個隱層的多層感知網絡並實現各種模式的識別和認知。
模型評價方面,選用AUC、Precision、Recall、Accuracy、F1-measure等指標。其中AUC[9](Area under Curve)是ROC曲線下的面積,介於0和1之間;AUC值表示將兩樣本正確分類的概率,AUC值越大說明模型分類性能越好。其他指標均是從不同角度衡量模型性能,這裡不再詳細說明。
3、建模結果分析
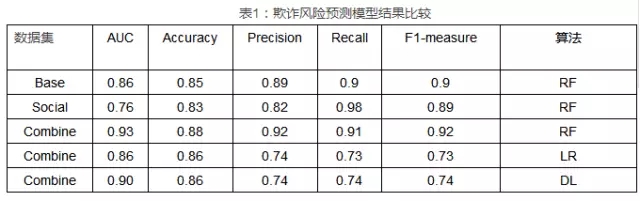
如下表所示,前三列數據為應用隨機森林(RF)算法在不同數據集上進行的三組模型輸出結果。比較結果數據可以發現,通過整合社交屬性信息模型各項評價指標較基礎信息模型結果均有大幅度提升。不同於基礎信息,社交維度重在刻畫實體在網絡中的關係,其加工指標在建模後呈現出與欺詐風險相關的強特徵關係。建模結果中AUC提升7個百分點,F1-measure提升2個百分點,充分驗證了建立多維度視角對於提升客戶欺詐風險識別能力的有效性。更重要的是,伴隨大數據的採集和處理,可以從深度和廣度上對客戶欺詐風險認知進一步補強,進而持續優化模型的底層數據源。
後面三組數據是在整合數據集上應用三種不同算法,整體表現邏輯回歸算法較弱,深度學習居中,隨機森林表現最優。結果表明目前模型輸入特徵與預測目標關聯性較好,並且總體特徵數量為數十個的量級,還不足以發揮深度學習海量特徵無監督優化選擇的特性,相比之下隨機森林、GBDT[ 10]等集成學習算法表現更為突出。
四、欺詐監控數據產品
大數據在實際應用中體現出強產品化的特點,通過構建反欺詐數據產品能夠快速實現決策引擎的功能;同時原始數據從積累到建模均與該數據產品關聯,用戶畫像建立和持續豐富也與反欺詐業務場景相結合。數據產品通過可視化技術實現自助式分析能力,在數據價值轉化為業務行動過程中發揮橋樑作用。
針對信用卡申請反欺詐場景,設計專項數據產品對接相關業務系統。數據產品提供全國進件審批疑似欺詐情況分佈圖,實時獲得所關注區域的欺詐進件分佈、欺詐發展趨勢、欺詐比重等動態。另外,提供分地區信息概要、進件詳情、明細檢索和社交網絡檢索等功能,能夠在系統頁面查詢基礎指標統計圖(手機和電話特徵分佈)、不同模型輸出的欺詐風險概率值、進件基本信息、進件網絡特徵、社交指標統計(一度、二度、最短路徑)等內容。

圖3 審批疑似欺詐情況分佈圖
五、總結與展望
新形勢下銀行業務面臨的欺詐風險演化出更多的表現形式和作案手法,亟需對傳統的欺詐風險防控手段進行“智能化”升級改造。我們基於大數據挖掘方法,綜合應用社交網絡分析和機器學習算法進行風險量化預測;客戶識別角度綜合基礎維度和社交維度信息,技術角度應用隨機森林、深度學習等算法大幅提升預測準確性,共同構成“會思考“的風控模型。模型能夠進一步區分欺詐特徵,提升信用卡申請欺詐偵測能力,該模型構建在銀行風險防範和反欺詐領域具有一定的推廣價值。
在下一步研究與實踐過程中,我們將結合更多銀行內外部數據以完善社交網絡特徵,對客戶進行更加全面的特徵刻畫將有助於復雜機器學習算法發揮威力;同時,將在業務系統部署智能化反欺詐監控模塊,通過數據產品提供欺詐進件分佈、欺詐發展趨勢、欺詐比重等動態場景以輔助決策,利用數據價值驅動支持業務的發展與轉型。
參考文獻:
[1] 何毅勇, 餘挈. 關於銀行業反欺詐的思考[J]. 銀行家, 2013, 32(4): 32-6.
[2] 陳世知. 美國信用卡產業中的反欺詐管理[J]. 中國信用卡, 2008, 12(4): 64-7.
[3] ALPAYDIN E. Introduction to Machine Learning (AdaptiveComputation and Machine Learning) [M]. MIT Press, 2004.
[4] DELAMAIRE L, ABDOU H, POINTON J, et al. Credit card fraud anddetection techniques: a review [J]. Banks & Bank Systems, 2009,
[5] VON AHN L. Augmented intelligence: the Web and human intelligence[J]. Philosophical Transactions of the Royal Society of London A: Mathematical,Physical and Engineering Sciences, 2013, 371(1987): 20120383.
[6] MATTBEWA.RUSSELL, 拉塞爾. 挖掘社交網絡[M]. 東南大學出版社, 2011.
[7] LIAW A, WIENER M. Classification and regression by randomForest[J]. R news, 2002, 2(3): 18-22.
[8] LECUN Y, BENGIO Y, HINTON G. Deep learning [J]. Nature, 2015,521(7553): 436-44.
[9] BRADLEY A P. The use of the area under the roc curve in theevaluation of machine learning algorithms [J]. Pattern Recognition, 1997,30(7): 1145-59.
[10] FRIEDMAN J H. Stochastic gradient boosting [J]. ComputationalStatistics & Data Analysis, 2002, 38(4): 367-78.
轉貼自: 煉數成金


留下你的回應
以訪客張貼回應