
摘要: Algorithmic biases that lead to unfair or arbitrary outcomes take many forms. But we also have many strategies and techniques to combat them.

Algorithmic bias is one of the AI industry’s most prolific areas of scrutiny. Unintended systemic errors risk leading to unfair or arbitrary outcomes, elevating the need for standardized ethical and responsible technology — especially as the AI market is expected to hit $110 billion by 2024.
There are multiple ways AI can become biased and create harmful outcomes.
First is the business processes itself that the AI is being designed to augment or replace. If those processes, the context, and who it is applied to is biased against certain groups, regardless of intent, then the resulting AI application will be biased as well.
Secondly, the foundational assumptions the AI creators have about the goals of the system, who will use it, the values of those impacted, or how it will be applied can insert harmful bias. Next, the data set used to train and evaluate an AI system can result in harm if the data is not representative of everyone it will impact, or if it represents historical, systemic bias against specific groups.
Finally, the model itself can be biased if sensitive variables (e.g., age, race, gender) or their proxies (e.g., name, ZIP code) are factors in the model’s predictions or recommendations. Developers must identify where bias exists in each of these areas, and then objectively audit systems and processes that lead to unfair models (which is easier said than done as there are at least 21 different definitions of fairness).
To create AI responsibly, building in ethics by design throughout the AI development lifecycle is paramount to mitigation. Let’s take a look at each step.
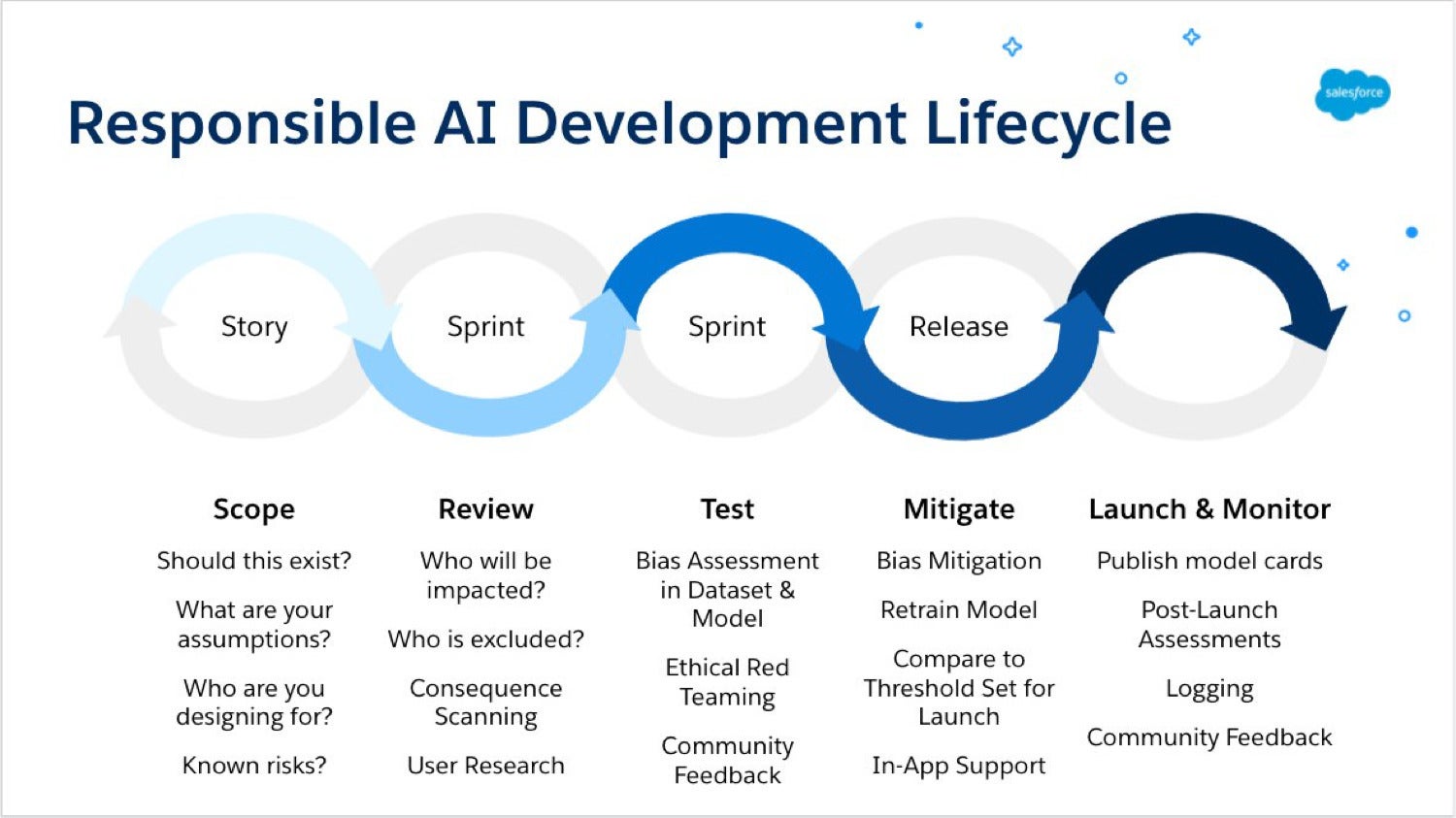
▲The responsible AI development lifecycle in an agile system.(來源:infoworld.com)
Scope
With any technology project, begin by asking, “Should this exist?” and not just “Can we build it?”
We don’t want to fall into the trap of technosolutionism — the belief that technology is the solution to every problem or challenge. In the case of AI, in particular, one should ask if AI is the right solution to achieve the targeted goal. What assumptions are being made about the goal of the AI, about the people who will be impacted, and about the context of its use? Are there any known risks or societal or historical biases that could impact the training data required for the system? We all have implicit biases. Historical sexism, racism, ageism, ableism, and other biases will be amplified in the AI unless we take explicit steps to address them.
But we can’t address bias until we look for it. That’s the next step.
Review
Deep user research is needed to thoroughly interrogate our assumptions. Who is included and represented in data sets, and who is excluded? Who will be impacted by the AI, and how? This step is where methodologies like consequence scanning workshops and harms modeling come in. The goal is to identify the ways in which an AI system can cause unintended harm by either malicious actors, or by well-intentioned, naïve ones.
What are the alternative but valid ways an AI could be used that unknowingly causes harm? How can one mitigate those harms, especially those that may fall upon the most vulnerable populations (e.g., children, elderly, disabled, poor, marginalized populations)? If it’s not possible to identify ways to mitigate the most likely and most severe harms, stop. This is a sign that the AI system being developed should not exist.
Test
There are many open-source tools available today to identify bias and fairness in data sets and models (e.g., Google’s What-If Tool, ML Fairness Gym, IBM’s AI 360 Fairness, Aequitas, FairLearn). There are also tools available to visualize and interact with data to better understand how representative or balanced it is (e.g., Google’s Facets, IBM AI 360 Explainability). Some of these tools also include the ability to mitigate bias, but most do not, so be prepared to purchase tooling for that purpose.
Red teaming comes from the security discipline, but when applied in an ethical use context, testers attempt to use the AI system in a way that will cause harm. This exposes ethical (and potentially legal) risks that you must then figure out how to address. Community juries are another way of identifying potential harm or unintended consequences of an AI system. The goal is to bring together representatives from a diverse population, especially marginalized communities, to better understand their perspectives on how any given system will impact them.
Mitigation
There are different ways to mitigate harm. Developers may choose to remove the riskiest functionality or incorporate warnings and in-app messaging to provide mindful friction, guiding people on the responsible use of AI. Alternatively, one may choose to tightly monitor and control how a system is being used, disabling it when harm is detected. In some cases, this type of oversight and control is not possible (e.g., tenant-specific models where customers build and train their own models on their own data sets).
There are also ways to directly address and mitigate bias in data sets and models. Let’s explore the process of bias mitigation through three unique categories that can be introduced at various stages of a model: pre-processing (mitigating bias in training data), in-processing (mitigating bias in classifiers), and post-processing (mitigating bias in predictions). Hat tip to IBM for their early work in defining these categories.
Pre-processing bias mitigation
Pre-processing mitigation focuses on training data, which underpins the first phase of AI development and is often where underlying bias is likely to be introduced. When analyzing model performance, there may be a disparate impact happening (i.e., a specific gender being more or less likely to be hired or get a loan). Think of it in terms of harmful bias (i.e., a woman is able to repay a loan, but she is denied based primarily on her gender) or in terms of fairness (i.e., I want to make sure I am hiring a balance of genders).
Humans are heavily involved at the training data stage, but humans carry inherent biases. The likelihood of negative outcomes increases with a lack of diversity in the teams responsible for building and implementing the technology. For instance, if a certain group is unintentionally left out of a data set, then automatically the system is putting one data set or group of individuals at a significant disadvantage because of the way data is used to train models.
In-processing bias mitigation
In-processing techniques allow us to mitigate bias in classifiers while working on the model. In machine learning, a classifier is an algorithm that automatically orders or categorizes data into one or more sets. The goal here is to go beyond accuracy and ensure systems are both fair and accurate.
Adversarial debiasing is one technique that can be used at this stage to maximize accuracy while simultaneously reducing evidence of protected attributes in predictions. Essentially, the goal is to “break the system” and get it to do something that it may not want to do, as a counter-reaction to how negative biases impact the process.
For example, when a financial institution is attempting to measure a customer’s “ability to repay” before approving a loan, its AI system may predict someone’s ability based on sensitive or protected variables like race and gender or proxy variables (like ZIP code, which may correlate with race). These in-process biases lead to inaccurate and unfair outcomes.
By incorporating a slight modification during training, in-processing techniques allow for the mitigation of bias while also ensuring the model is producing accurate outcomes.
Post-processing bias mitigation
Post-processing mitigation becomes useful after developers have trained a model, but now want to equalize the outcomes. At this stage, post-processing aims to mitigate bias in predictions — adjusting only the outcomes of a model instead of the classifier or training data.
However, when augmenting outputs one may be altering the accuracy. For instance, this process might result in hiring fewer qualified men if the preferred outcome is equal gender representation, rather than relevant skill sets (sometimes referred to as positive bias or affirmative action). This will impact the accuracy of the model, but it achieves the desired goal.
Launch and monitor
Once any given model is trained and developers are satisfied that it meets pre-defined thresholds for bias or fairness, one should document how it was trained, how the model works, intended and unintended use cases, bias assessments conducted by the team, and any societal or ethical risks. This level of transparency not only helps customers trust an AI; it may be required if operating in a regulated industry. Luckily, there are some open-source tools to help (e.g., Google’s Model Card Toolkit, IBM’s AI FactSheets 360, Open Ethics Label).
Launching an AI system is never set-and-forget; it requires ongoing monitoring for model drift. Drift can impact not only a model’s accuracy and performance but also its fairness. Regularly test a model and be prepared to retrain if the drift becomes too great.
Getting AI right
Getting AI “right” is difficult, but more important than ever. The Federal Trade Commission recently signaled that it might enforce laws that prohibit the sale or use of biased AI, and the European Union is working on a legal framework to regulate AI. Responsible AI is not only good for society, it creates better business outcomes and mitigates legal and brand risk.
AI will become more prolific globally as new applications are created to solve major economic, social, and political challenges. While there is no “one-size-fits-all” approach to creating and deploying responsible AI, the strategies and techniques discussed in this article will help throughout various stages in an algorithm’s lifecycle — mitigating bias to move us closer to ethical technology at scale.
At the end of the day, it is everyone’s responsibility to ensure that technology is created with the best of intentions, and that systems are in place to identify unintended harm.
轉貼自Source: infoworld.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance
 cherrylove
cherrylove 
留下你的回應
以訪客張貼回應