
摘要: 普林斯頓大學最近提出的 NeST 方法從新的角度爲神經網絡優化打開了方向。研究人員提出的新技術可以用「種子」神經網絡爲基礎,對特定數據集自動生成最優化的神經網絡,這些生成的模型在性能上超過此前業內最佳水平,同時資源消耗與模型尺寸相比同類模型小了一個數量級。研究人員稱,NeST 方法在工作過程中與人類大腦的成長和處理任務方式非常相近。

過去十幾年,神經網絡變革了大量的研究領域,例如計算機視覺、語音識別、機器人控制等。神經網絡通過多層抽象從數據集中提取智能的能力甚至能帶來超越人類的智能。因此,神經網絡逐漸成爲了現代人工智能的基石。
從給定的數據集中衍生出的神經網絡架構對其最終的表現有極大的影響。下表中對比了 2012-2016 年 ImageNet ILSVRC 競賽中的數種知名神經網絡。從網絡的深度、參數量、連接量、top-5 錯誤率表現 5 大維度對各種網絡架構做了描述。

表 1:ILSVRC 競賽中多種神經網絡架構與表現的對比
如何從給定的數據集中高效地得到合適的神經網絡架構雖然是一個極爲重要的課題,但也一直是個開放性難題,特別是對大型數據集而言。普林斯頓的研究人員得到神經網絡架構的傳統方式是:遍歷網絡架構的參數和對應的訓練,直到任務表現達到收益減少的點。但這種方法面臨三個問題:
1. 架構固定:大部分基於反向傳播的方法訓練的是網絡權重,而非架構。它們只是利用神經網絡權重空間中的梯度信息,而整個訓練過程中的神經網絡架構是固定的。因此,這樣的方法並不能帶來更好的網絡架構。
2. 漫長的提升:通過試錯的方法搜索合適的神經網絡架構非常的低效。這一問題隨着網絡的加深、包含數百萬的參數時愈爲嚴重。即使是最快的 GPU,每嘗試一種深度神經網絡動輒花費數十小時。要知道,GPU 目前是神經網絡訓練的主力。即使擁有足夠的算力與研究人員,找到適合某種應用的優秀架構也要花費數年時間,例如圖像領域,從 AlexNet 到 VGG、GoogLeNet、ResNet 的變革。
3. 大量的冗餘:大部分神經網絡的參數都過量了。即使是圖像分類任務中最知名的網絡(例如,LeNets、AlexNet、VGG),也面臨着大量的存儲和計算冗餘的問題。例如,斯坦福大學博士韓鬆等人 2015 年的 NIPS 論文表示,AlexNet 中的參數量和浮點運算可分別減少 9 倍、3 倍,且不損失準確率。
爲了解決這些問題,普林斯頓研究員在這篇論文中提出了中全新的神經網絡合成工具 NeST,既訓練神經網絡權重又訓練架構。受人腦學習機制的啓發,NeST 先從一個種子神經網絡架構(出生點)開始合成。它能讓神經網絡基於梯度信息(嬰兒大腦)生成連接和神經元,以便於神經網絡能快速適應手頭問題。然後,基於量級信息(成人大腦),它修剪掉不重要的連接和神經元從而避免冗餘。這使得 NeST 能夠生成緊湊且準確的神經網絡。作者們通過在 MNIST 和 ImageNet 數據集上的實驗表明,NeST 能夠極大的減少神經網絡的參數量和浮點運算需求,同時保證或略微提升模型的分類準確率,從而極大地削減了存儲成本、推理運行時間與能耗。
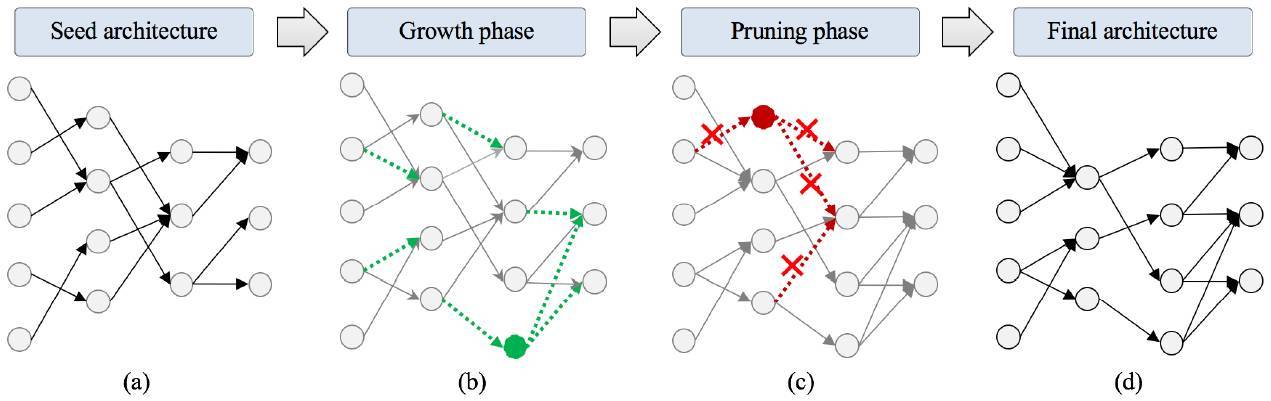
圖 1:NeST 架構合成流程的展示
如上圖所示,NeST 先從一種種子架構開始(圖 1a)。種子架構一般是一種稀疏的、局部連接的神經網絡。然後,它在兩個連續階段合成神經網絡:(i) 基於梯度的成長階段;(ii) 基於量級的修剪階段。在成長階段,架構空間中的梯度信息被用於漸漸成長出新的連接、神經元和映射圖,從而得到想要的準確率。在修剪階段,神經網絡繼承成長階段合成的架構與權重,基於重要性逐次迭代去除冗餘連接與神經元。最終,得到一個輕量神經網絡模型後 NeST 停止,該模型既不損失準確率,也是相對全連接的模型。

算法 1 展示了增長-剪枝合成算法的細節。sizeof 提取參數總量,並在驗證集上測試神經網絡的準確度。在進行合成之前,我們可對最大尺寸 S 和期望準確度 A 進行約束。下圖給出了算法主要結構。
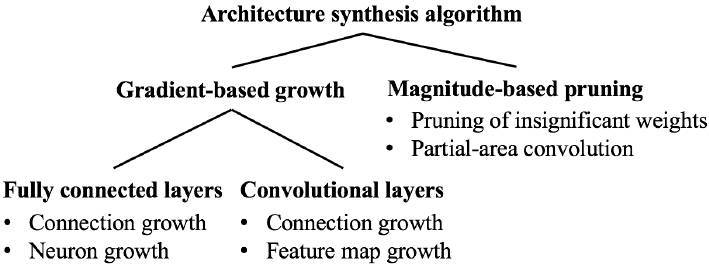
圖 2. NeST 中神經網絡生成算法的主要組成部分
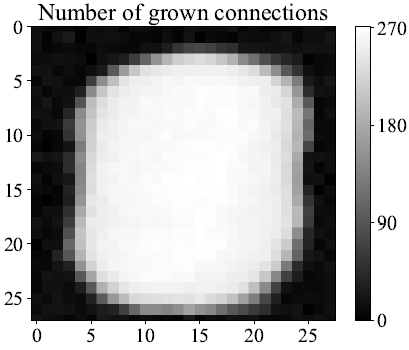
圖 3. LeNet-300-100 上,從輸入層到第一層上生長的連接。
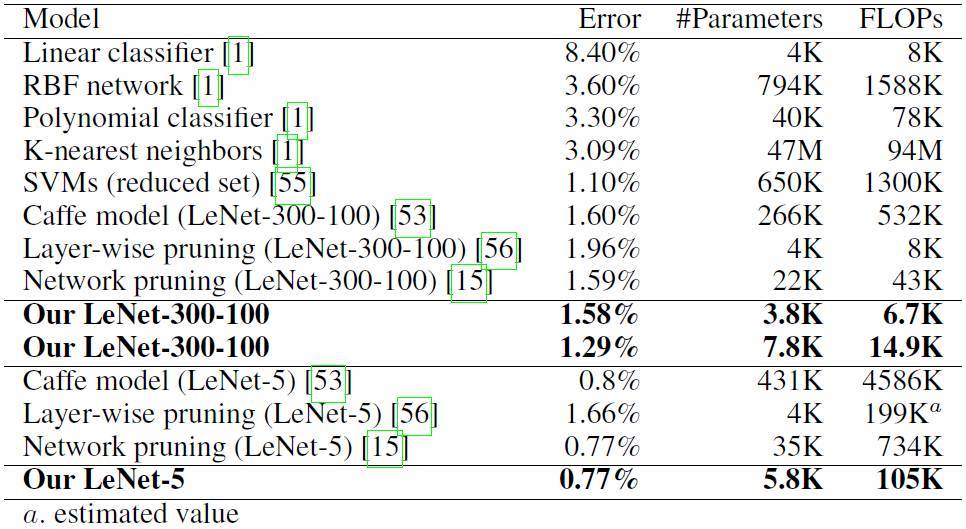
表 4. MNIST 不同的推導模型
人類大腦的複雜結構爲現代人工智能的發展提供了無數啓發。神經元概念的基礎、多層神經網絡結構甚至卷積核都源於對生物體的模仿。普林斯頓大學的研究人員表示,NeST 從人腦結構中獲得了三個方面的啓發。
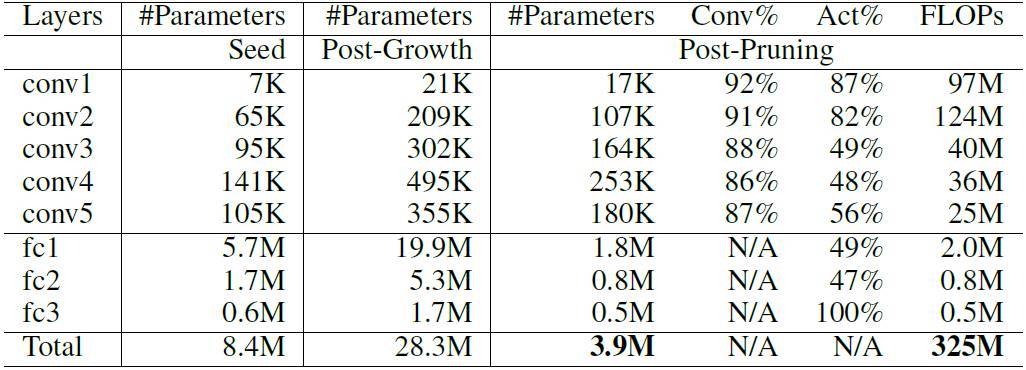
表 5. 合成的 AlexNet(錯誤率 42.76%)
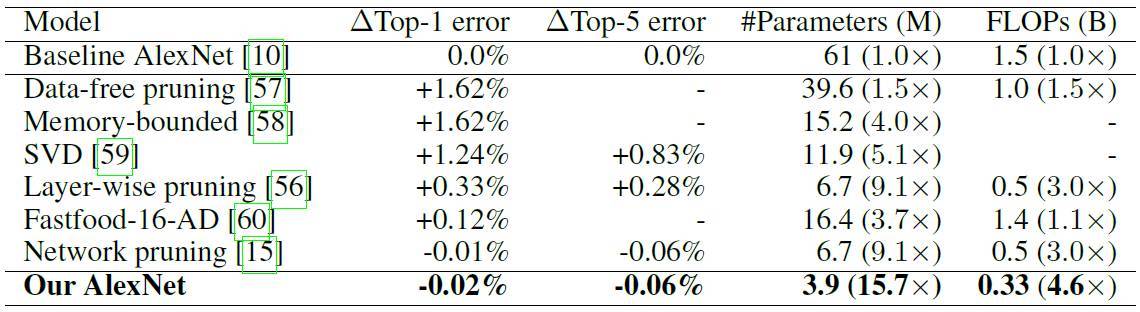
表 6. 在 ImageNet 上不同基於 AlexNet 推理模型的表現
首先,大腦中突觸聯繫的數量在不同的人類年齡段上有所不同。在嬰兒剛出生時,突觸聯繫的數量增長很快,幾個月後開始下降,隨後逐漸保持穩定。神經網絡在 NeST 中的學習過程非常接近於這一曲線。最初的種子神經網絡簡單而稀疏,就像嬰兒出生時的大腦。在生長階段,其中的連接和神經元數量因爲外界信息而大量增長,這就像人類嬰兒的大腦對外界刺激做出反應。而在修剪階段它減少了突觸連接的數量,擺脫了大量冗餘,這與嬰兒形成成熟大腦的過程是類似的。爲了更清晰地解釋這一過程,研究人員在圖 12 中展示了 LeNet-300-100 在新方法處理過程中的連接數量變化。
第二,大腦中的大部分學習過程都是由神經元之間的突觸重新連接引起的。人類大腦每天都會新增和清除大量(高達 40%)的突觸連接。NeST 喚醒新的連接,從而在學習過程中有效地重連更多的神經元對。因此,它模仿了人類大腦中「重新連接學習」的機制。
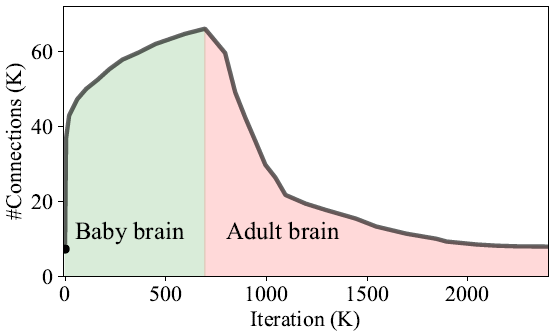
圖 12. LeNet-300-100 的連接數與迭代次數對比
第三,大腦中只有一小部分神經元在所有時間裏都是活躍的,這種現象被稱爲稀疏神經元反應。這種機制允許人類大腦在超低功耗下運行(20W)。而全連接的神經網絡在推理中存在大量無意義的神經元反應。爲了解決這個問題,普林斯頓的研究者們在 NeST 中加入了一個基於重要性的神經元/連接修剪算法來消除冗餘,從而實現了稀疏性和緊湊性。這大大減少了存儲和計算需求。
論文:NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm
論文連結:https://arxiv.org/abs/1711.02017
總結:
神經網絡(Neural Networks,NN)已經對機器學習的各類應用產生了廣泛影響。然而,如何爲大型應用尋找最優神經網絡架構的問題在幾十年來一直未被解決。傳統上,我們只能通過大量試錯來尋找最優的 NN 架構,這種方式非常低效,而生成的 NN 架構存在相當數量的冗餘組織。爲了解決這些問題,我們提出了神經網絡生成工具 NeST,它可以爲給定的數據集自動生成非常緊湊的體系結構。
NeST 從種子神經網絡架構開始,它不斷基於梯度增長和神經元與連接的重要性修剪來調整自身性能。我們的實驗證明,NeST 能以多類種子架構爲基礎,產生出準確而小尺寸的神經網絡。例如,對於 MNIST 數據集,LeNet-300-100(LeNet-5)架構,我們的方法將參數減少了 34.1 倍(74.3 倍),浮點運算需求(FLOP)減少了 35.8 倍(43.7 倍)。而在 ImageNet 數據集,AlexNet 架構上,NeST 讓算法參數減少了 15.7 倍,FLOP 減少了 4.6 倍。以上結果均達成了目前業內最佳水平。
轉貼自: 壹讀
 jamesmartin
jamesmartin 
留下你的回應
以訪客張貼回應