
摘要: 藉由犧牲個人利益來極大化團隊利益,追求團隊的目標,是人類社會進步的關鍵。然而,合作不再是人類的專利, DeepMind 用 2 對 2 足球賽訓練 AI ,要讓 AI 學會團隊協作。起初個別的 AI 也是以極大化自己利益,後來學會了合作,以最大化團隊利益為目標。雖然這項研究只有 4 個 AI 參與,但它的意義是讓 AI 學會協作,為未來的更多 AI 協作與應用打下基礎。

從足球競技到戰爭,團隊合作一直被認為是人類社會進步的基石。基於長遠的共同目標,弱化甚至犧牲個人利益,促成了人類作為共同體的最大利益。
DeepMind 也正嘗試讓人工智慧學會這一點,並且選擇了最有可能顯示團隊合作的考核方式——足球比賽。
22 日凌晨, DeepMind 發佈了最新研究:證明了在足球情境下,一種基於分佈式代理的連續控制培訓框架,結合獎勵渠道的自動優化,可以實現多智能體(multi-agent)端到端的學習。
簡單來說就是, DeepMind 設置了情境,讓多個 AI 一起踢足球賽。並且提前設置了規則, 獎勵整支「足球隊」而不去鼓勵某個「AI 球員」的個人成績 ,以促成整個球隊的進步。用這種方式證明了, AI 也是可以相互合作的!

這篇 論文 被 ICLP 2019 收錄。
通過踢足球競爭,訓練 AI 多方協作
多智能體透過協作,完成團隊最優目標並不是一個陌生的話題,去年,OpenAI 就曾發佈了由五個神經網絡組成的 DOTA 團戰 AI 團隊—— OpenAI Five ,並在 5v5 中擊敗了頂級人類玩家團隊。比賽中, OpenAI Five 也展示了,在勝利是以摧毀防禦塔為前提的遊戲中,犧牲「小兵」利益是可以被接受的,也就是說, AI 是可以朝著長期目標進行優化的。
DeepMind 的最新研究進一步專注於多智能體這一領域。他們組織了無數場 2v2 的 AI 足球比賽,並設定了規則,一旦有一方得分或者比賽超過 45 秒,比賽就結束。
DeepMind 稱,透過去中心化的、基於群體的訓練可以使得代理人的行為不斷發展:從隨機,簡單的追球,到最後的簡單「合作」。他們的研究還強調了在連續控制的大規模多智能體訓練中遇到的幾個挑戰。
值得一提的是, DeepMind 透過設置自動優化的簡單獎勵,不鼓勵個體,而去鼓勵合作行為和團隊整體的成績,可以促成長期的團隊行為。
在研究中通過引入一種「基於單獨折扣因子來形成自動優化獎勵的思想」,可以幫助他們的代理從一種短視的訓練方式,過渡到一種長時間但更傾向於團隊合作的訓練模式當中。
DeepMind 也進一步提出了一個以博弈論原理為基礎的評估方案,可以在沒有預定義的評估任務或人類基線的情況下評估代理的表現。
多智能體強化學習的行為,取決於報酬獎勵的設置
將足球比賽看做一個多智能體強化學習(MARL)的過程,模擬一個可交互的環境,智能主體透過學習與環境互動,然後優化自己累計獎勵。 MARL 的主題思想是協作或競爭,亦或兩者皆有。選擇什麼樣的行為,完全取決於「報酬獎勵」的設置。 MARL 的目標是典型的馬可夫完美均衡(Markov perfect equilibrium)。大致意思是尋找隨機博弈中達到均衡條件的混合策略集合。
具體意思是:博弈參與者的行動策略有馬可夫特點,這意味著每個玩家的下一個動作是根據另一個玩家的最後一個動作來預測的,而不是根據先前的行動歷史來預測的。 馬可夫完美均衡是:基於這些玩家的動作尋找動態均衡。
DeepMind 在 github 上 發佈 了他們使用的 MuJoCo Soccer 環境,這是一個競爭協作多智能體交互的開源研究平台,在機器學習社區已經得到了相當廣泛的使用。
DeepMind 採用優化評估,提升 AI 表現
為了有效地評估學習團隊,DeepMind 選擇 優化評估 方法,所選團隊都是以前由不同評估方法產生的 10 個團隊,每個團隊擁有 250 億次的學習經驗。他們在 10 個團隊中收集了一百萬種比賽情況。
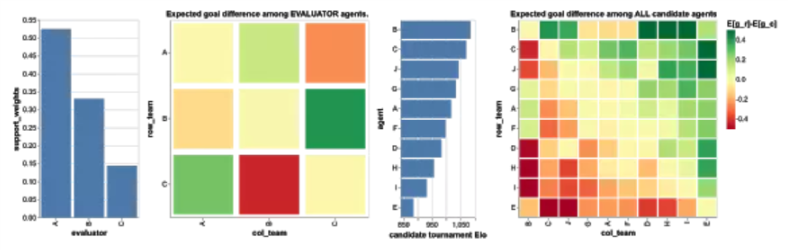
上圖顯示了支持團隊的 3 個智能體顯示的成對預期目標差異。納許均衡要求 3 個團隊的權重都是非零的,這些團隊協作展示了具有非傳遞性能的不同策略,這是評估方案中並不存在的:團隊 A 在 59.7% 的比賽中贏得或打平團隊 B ;團隊 B 在 71.1% 的比賽中贏得或打平團隊 C ;團隊 C 在 65.3% 的比賽中贏得或打平團隊 A 。他們展示了團隊 A、B 和 C 之間的示例比賽的記錄,可以定性地量化其策略的多樣性。
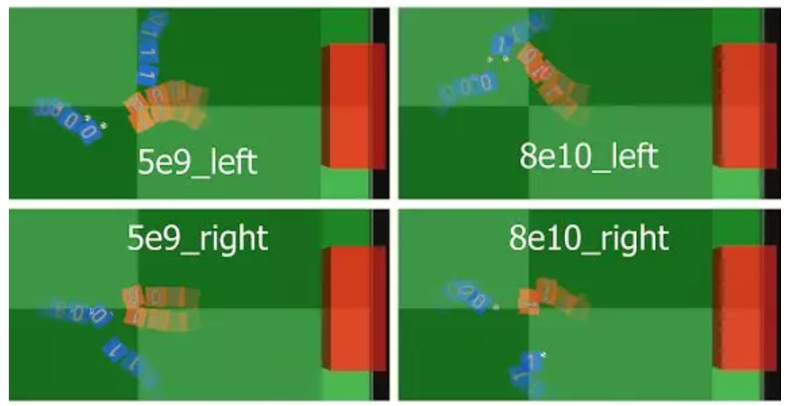
在上圖中, DeepMind 展示了代理行為的典型軌跡:在 5B 步驟中,當代理更個性化地行動時,我們觀察到無論 blue1 的位置如何, blue0 總是試圖自己運球。但在訓練的後期, blue0 則積極尋求團隊合作,其行為呈現出由其隊友驅動的特點,顯示出高水平的協調精神。特別是在「8e10_left」這一場比賽中中, DeepMind 稱他們觀察到了兩次連續傳球(blue0 到 blue1 和後衛),這是在人類足球比賽中經常出現的 2 對 1 撞牆式配合。
研究意義:訓練 AI 的協調行為
DeepMind 此項研究意義重大,將 2v2 足球領域引入多智能體協作是以前沒有過的研究,透過強化學習研究,利用競爭與合作來訓練獨立智能個體,展示了團隊的協調行為。
這篇論文也證明了一種基於連續控制的分佈式集群訓練框架,可以結合獎勵路逕自動優化,因此,在這種環境下可以進行進行端到端的學習。
其引入了一種思想,將獎勵方向從單策略行為轉變為長期團隊合作。引入了一種新的反事實政策評估來分析主題策略行為。評估強調了匹配結果中的非傳遞性和對穩健性的實際需求。
DeepMind 開源的訓練環境可以作為多智能體研究的平台,也可以根據需要擴展到更複雜的智能體行為研究,這為未來的研究打下堅實的基礎。
轉貼自: BuzzOrange

留下你的回應
以訪客張貼回應