
摘要: 堆疊是集成多個分類法或回歸模型的方式。有很多方法可以集成模型,眾所周知的模型有Bagging或Boosting。Bagging允許多個具有高方差類似的分類模型中取平均以減少差異。Boosting建立多個增量模型,以減少誤差,同時保持方差小。
堆疊是集成多個分類法或回歸模型的方式。有很多方法可以集成模型,眾所周知的模型有Bagging或Boosting。Bagging允許多個具有高方差類似的分類模型中取平均以減少差異。Boosting建立多個增量模型,以減少誤差,同時保持方差小。
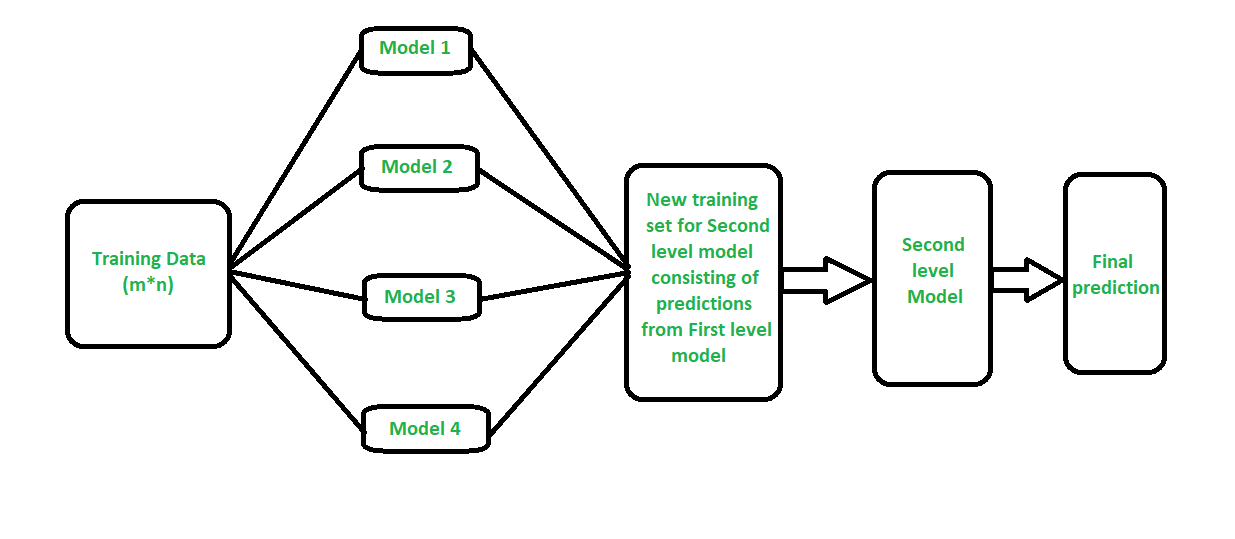
堆疊(有時稱為堆疊泛化)是不同的範例。堆疊的一點是要對同個問題探索不同模型的空間。這個想法是,你可以以不同類型的模型去攻略一個機器學習問題,不同模型能夠學習問題的某些部分,但不是學習到問題的全部。所以你可以建立多個不同的學習方式並使用它們來構建中間預測,一個學習模型產生一個預測。然後使用中介預測去訓練一個新模型去學同個目標。
1.我們的訓練數據分成K-部分就像K-fold交叉驗證。
2.一個基本模型配適在K-1部份和預測第K部分。
3.此動作重複在訓練數據的每個部分。
4.然後,將基礎模型配適在整個訓練數據集來計算其測試集的績效。
5.我們重複了其他基本模型在上面3個步驟。
6.從訓練組的預測被用作特徵在於用於所述第二級模型。
7.第二級模型是用來做的測試集的預測。
Blending
Blending是一種類似堆疊的方法。
1.訓練集分成訓練和驗證集。
2.我們訓練trainu資料集的基礎模型。
3.我們只對驗證集和測試集做預測。
4.驗證集的預測被用作特性來構建一個新的模型。
5.該模型是使用預測值作為特徵來做出測試組的最終預測。
轉貼自: geeksforgeeks
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應