
摘要: 有些公司儘管擁有出色的人工智能業務理念,但當他們意識到自己沒有足夠的數據時,卻會慢慢變得沮喪......然而,解決方案確實存在!本文的目的是簡要介紹其中一些(在實踐中被證明有效的那些)而不是列出所有現有的解決方案。

數據稀缺問題非常重要,因為數據數據是任何AI項目的核心。數據集的大小通常是ML項目表現不佳的原因。
大多數情況下,與數據相關的問題是無法實現優秀人工智能項目的主要原因是,沒有相關數據或收集過程太困難且耗時。
監督式機器學習模型被應用於應對各種商業上的挑戰。但是,這些模型需要大量數據,其性能比很大程度上取決於可用的培訓數據。在許多情況下,很難創建足夠大的訓練數據集。
另一個問題是項目分析師傾向於低估處理常見問題所需的數據量。在為大公司工作時收集數據更加複雜......
所以需要多少資料?
大概需要自由度的10倍。模型越複雜,您就越容易過度擬合,但可以通過驗證來避免。但是,根據用例可以使用更少的數據。
處理缺失值將取決於某些“成功”標準。此外,這些標準因不同的數據集而異,甚至適用於不同的應用,如識別,分割,預測,分類等。
重要的是要理解"沒有完美的方法來處理遺失的數據"。
當涉及到預測技術時,只有在沒有完全隨機觀察缺失值且使用與被解釋變數有某種關係的變量來估算這些缺失值,否則它可能產生不精確的估計。
通常,可以使用不同的機器學習算法來確定缺失值。這可以通過將缺少的特徵轉換為標籤本身,現在使用沒有缺失值的列來預測具有缺失值的列
如果你決定構建一個基於AI的解決方案,那麼在某些時候你將面臨缺乏數據或缺少數據的問題,但幸運的是,有很多方法可以將補足數據。
缺少資料?
如上所述,不可能合理地估計AI項目所需的最小數據量。顯然,項目的本質將影響您需要的數據量。例如,文本,圖像和視頻通常需要更多數據。但是,為了做出準確的估計,還應考慮許多其他因素。
要預測的類別數
您的模型的預期輸出是多少?基本上,預測的類別越少越好。
模型績效
如果您計劃將產品投入生產,則需要更多產品。一個小數據集可能足以用於概念驗證,但在生產中,您需要更多數據。
通常,小數據集需要具有低複雜度(或高偏差)的模型,以避免將模型過度擬合到數據。 >
非技術性解決方案
在講解技術解決方案之前,讓我們分析一下我們可以做些什麼來增強您的數據集。這可能聽起來很明顯,但在開始使用AI之前,請嘗試通過開發外部和內部工具以及數據收集來盡可能多地獲取數據。如果您知道機器學習算法預期要執行的任務,則可以提前創建數據收集機制。
嘗試在組織內建立真正的數據文化。
要開始執行ML前,您可以依賴開源數據。有很多可用於ML的數據,一些公司開放讓所有人使用它。
如果您需要外部數據,與其他組織建立合作夥伴關係以獲取相關數據可能是有益的。形成合作關係的成本顯然會花費你一些時間,但獲得的專有數據將為任何競爭對手構成天然屏障。
創造一個有用的應用程序,開放它,使用它所獲取的數據
可以使用的另一種方法是向客戶提供對雲端應用程序的訪問權限。進入應用程序的數據可用於構建機器學習模型。我以前的客戶為醫院建立了一個應用程序並使其免費。我們收集了大量數據,並設法為我們的ML解決方案創建了一個獨特的數據集。告訴客戶或投資者您已構建自己的獨特數據集確實很有幫助。
小型數據集
一些可以幫助從小數據集構建預測模型的常用方法是:
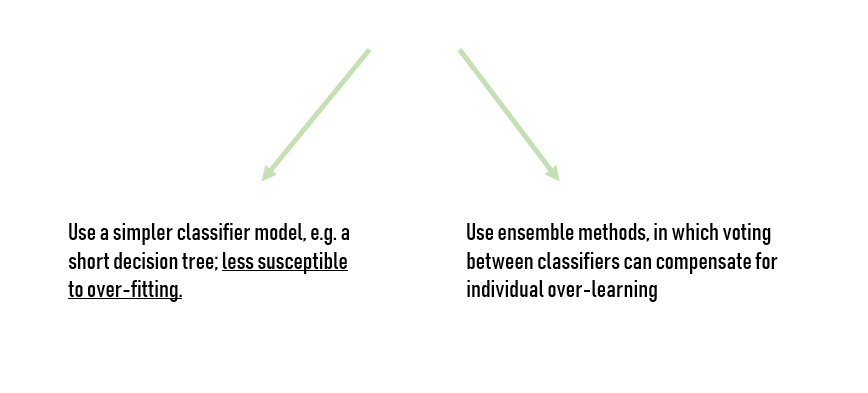
通常,機器學習算法越簡單,它就越能從小數據集中學習。從ML的角度來看,小數據需要具有低複雜度(或高偏差)的模型,以避免將模型過度擬合到數據。Naive Bayes算法是最簡單的分類器之一,因此從相對較小的數據集中學習效果非常好。
您還可以依賴其他線性模型和決策樹。實際上,它們在小型數據集上的表現也相對較好。基本上,簡單模型能夠比更複雜的模型(神經網絡)更好地從小數據集中學習,因為它們本質上是在努力學習更少資料。
對於非常小的數據集,貝式方法通常是同類中最好的,儘管結果可能對您選擇的先驗敏感。樸素的貝葉斯分類器和脊回歸是最好的預測模型。
對於小型數據集,您需要具有少量參數(低複雜性)和/或強大先驗的模型。您還可以將“先驗”解釋為您可以對數據行為方式做出的假設。

根據問題的確切性質和數據集的大小,確實存在許多其他解決方案。
遷移式學習
轉移學習使用來自相關學習任務的知識來改善性能,通常減少所需的訓練數據量。
遷移式學習技術很有用,因為它們允許模型使用從另一個數據集或現有機器學習模型(源域)獲得的知識對新域或任務(稱為目標域)進行預測。
當您沒有足夠的目標訓練數據時,應考慮轉移學習技術,源域和目標域有一些相似之處但不相同。
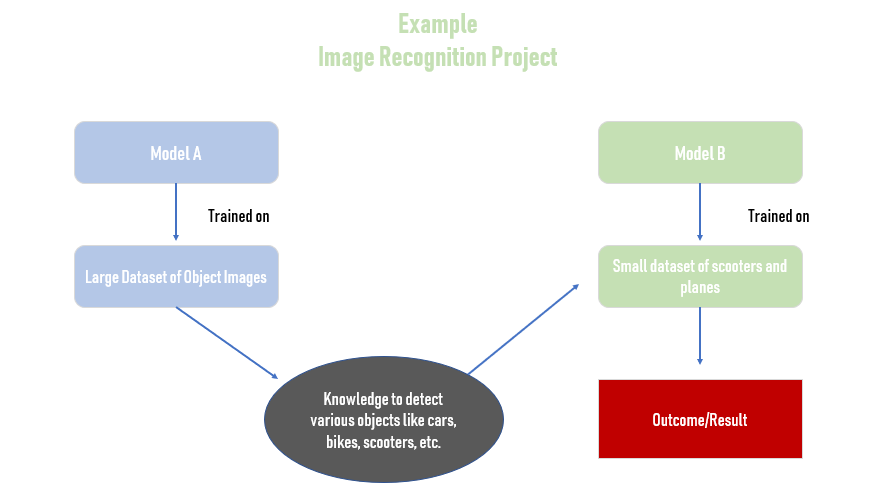
簡單的聚合模型或不同的數據集並不總是有效!如果現有數據集與目標數據非常不同,則新學習者可能會受到現有數據或模型的負面影響。
當您擁有可用於推斷知識的其他數據集時,遷移學習效果很好,但是當您根本沒有數據時會發生什麼?這是數據生成可以發揮作用的地方。它在沒有可用數據時使用,或者當您需要創建的數據超過您通過協議可以收集的數據時使用。
在這種情況下,修改存在的少量數據以創建該數據的變體以訓練模型。例如,汽車的許多圖像可以通過裁剪,裁剪,縮小尺寸,汽車的單個圖像來生成。
遺憾的是,缺乏高質量的標籤數據也是數據科學團隊面臨的最大挑戰之一,但通過使用轉移學習和數據生成等技術,可以克服數據稀缺性。
轉移學習的另一個常見應用是在跨客戶數據集上訓練模型。SaaS公司經常需要處理新客戶加入ML產品的問題。實際上,在新客戶收集到足夠的數據以實現良好的模型性能(可能需要幾個月)之前,很難提供價值
數據擴充
數據增加意味著增加數據點的數量。好處有有兩個:時間和準確性。每個數據收集過程都與成本相關聯。這個成本可以是美元,人力,計算資源以及過程中消耗的時間。

因此,我們不得不增加現有數據,以增加我們提供給ML分類器的數據大小,並補償進一步數據收集所涉及的成本。
您可以旋轉原始圖像,更改光照條件,以不同方式裁剪,因此對於一個圖像,您可以生成不同的子樣本。這樣您就可以減少過度擬合分類器。但是,如果您過度採樣(如SMOTE)生成人工數據,那麼您很可能會過度擬合。
合成數據
合成數據是指包含與“真實”對應物相同的模式和統計屬性的虛假數據。基本上,它看起來如此真實,幾乎不可能告訴它不是。
那麼合成數據有什麼意義呢?如果我們已經可以使用真實的資料為什麼還要合成資料呢?
當我們處理私人數據(銀行業務,醫療保健等)時,這使得在某些情況下使用合成數據成為更安全的開發方法。
合成數據主要用於實際數據不足或者您知道的特定模式沒有足夠的實際數據時。用於訓練和測試數據集的用法大致相同。
合成少數過採樣技術(SMOTE)和Modified-SMOTE是兩種產生合成數據的技術。簡而言之,SMOTE採用少數類數據點並創建新數據點,這些數據點位於由直線連接的任何兩個最近的數據點之間。
該算法計算特徵空間中兩個數據點之間的距離,將距離乘以0和1之間的隨機數,並將新數據點放置在對應的點。
為了生成合成數據,您可以通過模擬生成合成數據。數據類型很重要,因為它會影響整個過程的複雜性。
處理資料缺失時,問問自己是否有足夠的數據會揭示你以前可能從未發現的出入。弄清楚如何做到這一點會是個好主意。
轉貼自: Predict
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應