
摘要: 神經網絡是功能強大而又靈活的模型,在圖像,語音以及自然語言理解等學習任務上有良好的效果。儘管神經網絡很成功,但設計一個好的神經網絡仍然十分困難。為了能夠使設計神經網絡變得簡單,谷歌大腦團隊發表了一篇名為《Neural architecture search with reinforcement learning》的文章,該文章使用循環網絡來生成神經網絡中的模型描述,並用強化學習訓練這個RNN,以最大限度的提高驗證集中生成的架構的準確性。
該論文的作者之一Quoc V. Le是機器學習大牛吳恩達先生在史丹福大學時期的博士生,而雷鋒網了解到,該論文將會在今天的 ICLR會議上作為第四個Contributed talk進行討論。
以下為雷鋒網AI科技評論據論文內容進行的部分編譯。
論文摘要
過去幾年中,許多深度神經網絡在語音識別,圖像識別,機器翻譯等富有挑戰性的任務中取得極大的成功。伴隨著神經網絡的發展,研究人員的重點從特徵設計轉移到了架構設計,比如從SIFT和HOG算法,轉移到了AlexNet,VGGNet,GoogleNet,以及ResNet等網絡架構設計中。儘管這些方法似乎變得更簡單了,但設計網絡架構仍然需要大量的專業知識並耗費大量時間。
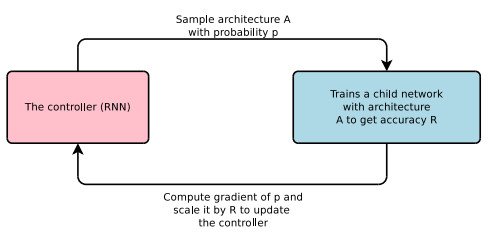
谷歌大腦團隊提出了神經架構搜索(Neural Architecture Search),使用基於梯度的方法以找到最優的架構,過程如上圖。由於神經網絡的結構可以由特定的變長字符串指代,因此可以使用循環神經網絡(控制器)生成該字符串。使用真實數據訓練由字符串指代的網絡(「子網絡」),並在驗證集上得到一個準確率。之後使用強化學習訓練RNN,將準確率作為reward信號,即可以計算策略梯度,以便更新控制器。因此,在下一個疊代周期,控制器有更大的可能會生成一個能夠得到更高準確率的架構。換種說法,控制器能夠學習如何改善它的搜索。
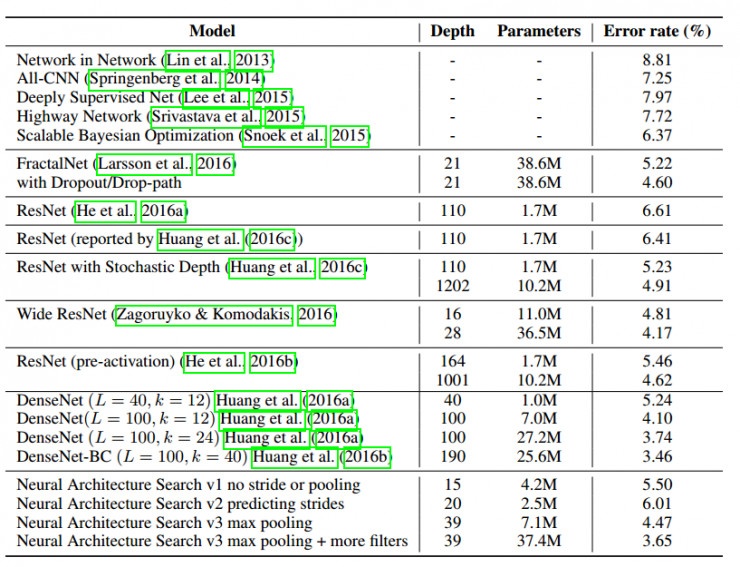
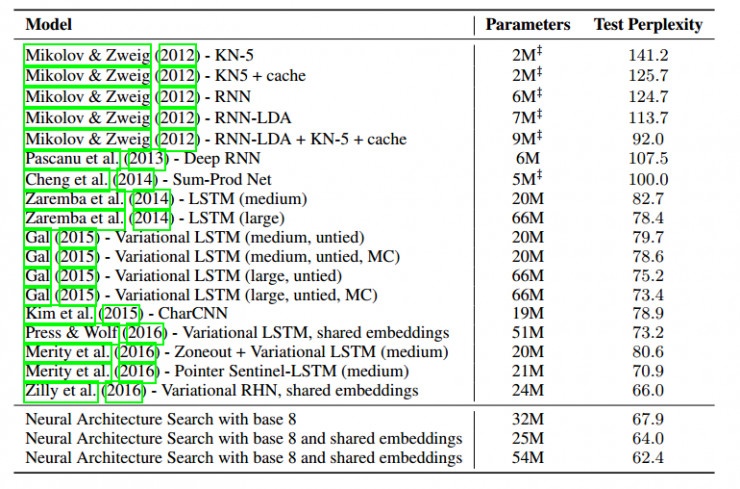
該論文的結果展示了神經架構搜索能夠設計出很好的模型,在CIFAR-10數據集上的圖像識別,神經架構搜索能夠找到一個新穎的卷積網絡模型,該模型比目前人工設計的最好的模型更好,在測試集上得到了3.84的錯誤率,同時速度是目前最好的人工模型的1.2倍。在Penn Treebank數據集的語言模型中,神經架構搜索設計出的模型比先前RNN和LSTM架構更好,困惑度(perplexity)為62.4,比目前最好的人工方法提高了3.6.
使用循環神經網絡生成模型描述
使用控制器生成神經網絡架構的超參數,為了靈活性,控制器選擇為循環神經網絡。下圖為預測只具有卷積層的前饋神經網絡,控制器將生成的超參數看作一系列符號。
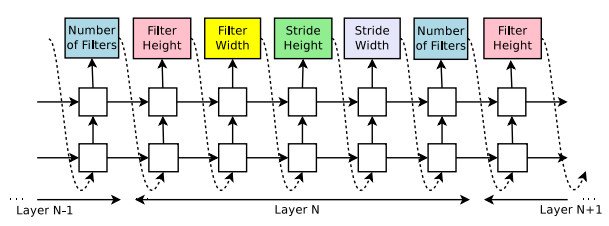

在實驗中,如果網絡的層數超過一定值,則生成架構會停止。該值遵循一定的策略,並隨著訓練過程增加。一旦控制器RNN完成了架構的生成,就開始構建並訓練具有該架構的神經網絡。在網絡收斂之後,記錄網絡在驗證集中的準確率,並對控制器RNN的參數進行優化,以使控制器所提出的架構的預期驗證準確率最大化。
使用強化學習進行訓練
控制器預測的模型描述可以被看作設計子網絡的一系列action。在訓練子網絡收斂之後,該子網絡會在保留數據集上得到一個準確度R。使用準確度R作為reward信號,並使用強化學習訓練控制器。
實驗結果
CIFAR-10數據集上的卷積架構學習
搜索空間為卷積結構,使用了非線性層以及批歸一化(batch normalization)。對於每個卷積層,控制器需要在[1,3,5,7]中選擇濾波器的寬度和高度,在[24,36,48,64]中選擇濾波器數量。
RNN控制器為兩層LSTM,每層有35個隱藏單元。使用學習率為0.0006的ADAM優化器訓練。控制器權值在-0.08到0.08之間平均初始化。並且進行分布式訓練,使用了800個GPU同時訓練800個網絡。當RNN控制器確定了一個架構之後,子網絡就被構建,並訓練50個周期。在控制器訓練過程中,控制器每確定1600個網絡架構,網絡的深度就增加2,初始的網絡深度為6。
在控制器訓練了12800個架構之後,得到了最高的驗證集準確率,與其他方法的準確率對比見下圖:
Penn Treebank數據集上循環網絡架構學習
訓練過程與CIFAR-10實驗基本相同,最終結果如下:
總結:該論文提供了一種使用RNN構建神經網絡模型的方法。通過使用循環神經網絡作為控制器,該方法可以靈活地在不同的結構空間中搜索。該方法在一些具有挑戰性的數據集上有著很好的性能,也為自動構建高質量神經網絡架構提供了一個新的研究方向。
評價:該篇論文是提交給會議的論文中最好的幾篇之一。評委們都很欣賞該想法,並認為實驗設計得嚴密,有趣,引人注意。尤其令人感興趣的是實驗結果表明生成模型的性能比目前廣泛使用的模型更好(例如LSTM)。
轉貼自: 壹讀

留下你的回應
以訪客張貼回應