
摘要: 蒙特婁大學Ian Goodfellow等學者提出「生成對抗網絡」(Generative Adversarial Networks,GANs)的概念,並逐漸引起AI業內人士的注意。

多篇重磅論文陸續發表
• Facebook、Open AI等AI業界巨頭也加入對GANs的研究;
• 它成為今年12月NIPS大會當之無愧的明星——在會議大綱中被提到逾170 次;
• GANs之父」Ian Goodfellow被公推為人工智慧的頂級專家;
業內另一位大神 Yan Lecun也對它稱讚,稱其為「20年來機器學習領域最酷的想法」。
現在,就連蘋果也跳上了GANs的彩車:蘋果有史以來第一篇公開發表的AI論文,講的是如何更好地利用GANs,來訓練AI圖像識別能力。這是繼蘋果本月初在NIPS大會上宣布「將對外公布AI研究成果」之後,為兌現諾言做出的行動。
那麼,GANs是如何從一個原本「不溫不火」的技術,成為今天人工智慧的主要課題之一?
我們對此進行了梳理,歸納了GANs從誕生到現在如何一步步走向技術成熟。以下是它發展路線中的大事件(主要研究進展):
1. GANs誕生

▲Ian Goodfellow
2014年6月,Ian Goodfellow等學者發表了論文《Generative Adversarial Nets》,題目即「生成對抗網絡」,這標誌著GANs的誕生。文中,Ian Goodfellow等作者詳細介紹了GANs的原理,它的優點,以及在圖像生成方面的應用。
那麼,什麼是GANs?
用Ian Goodfellow自己的話來說:
生成對抗網絡是一種生成模型(Generative Model),其背後基本思想是從訓練庫里獲取很多訓練樣本,從而學習這些訓練案例生成的機率分布。
而實現的方法,是讓兩個網絡相互競爭,『玩一個遊戲』。其中一個叫做生成器網絡(Generator Network),它不斷捕捉訓練庫里真實圖片的機率分布,將輸入的隨機噪聲(Random Noise)轉變成新的樣本(也就是假數據)。另一個叫做判別器網絡(Discriminator Network),它可以同時觀察真實和假造的數據,判斷這個數據到底是不是真的。
對不熟悉GANs的讀者,這番解釋或許有些晦澀。因此,雷鋒網特地找來AI博主Adit Deshpande的解釋,更加清楚直白:
GANs的基本原理是它有兩個模型:一個生成器,一個判別器。判別器的任務是判斷給定圖像是否看起來『自然』,換句話說,是否像是人為(機器)生成的。而生成器的任務是,顧名思義,生成看起來『自然』的圖像,要求與原始數據分布儘可能一致。
GANs的運作方式可被看作是兩名玩家之間的零和遊戲。原論文的類比是,生成器就像一支造假幣的團伙,試圖用假幣矇混過關。而判別器就像是警察,目標是檢查出假幣。生成器想要騙過判別器,判別器想要不上當。當兩組模型不斷訓練,生成器不斷生成新的結果進行嘗試,它們的能力互相提高,直到生成器生成的人造樣本看起來與原始樣本沒有區別。
早期的GANs模型有許多問題。Yan Lecun指出,其中一項主要缺陷是:GANs不穩定,有時候它永遠不會開始學習,或者生成我們認為合格的輸出。這需要之後的研究一步步解決。
2. 拉普拉斯金字塔(Laplacian Pyrami)的應用
GANs最重要的應用之一,是生成看起來『自然』的圖像,這要求對生成器的充分訓練。以下是 Ian Goodfellow等人的2014年論文中,生成器輸出的樣本:

可以看出,生成器在生成數字和人臉圖像方面做得不錯。但是,使用CIFAR-10資料庫生成的風景、動物圖片十分模糊。這是GANs早期的主要局限之一。
2015年6月 Emily Denton等人發表的研究《Deep Generative Image Models using Lapalacian Pyramid of Adversarial Networks》(「深度圖像生成模型:在對抗網絡應用拉普拉斯金字塔」)改變了這一點。研究人員提出,用一系列的卷積神經網絡(CNN)連續生成清晰度不斷提高的圖像,能最終得到高解析度圖像。該模型被稱為LAPGANs。
其中的拉普拉斯金字塔,是指同一幅圖像在不同解析度下的一系列過濾圖片。與此前GAN架構的區別是:傳統的GAN只有一個生成器 CNN,負責生成整幅圖像;而在拉普拉斯金字塔結構中,金字塔的每一層(某特定解析度),都有一個關聯的CNN。每一個CNN都會生成比上一層CNN更加清晰的圖像輸出,然後把該輸出作為下一層的輸入。這樣連續對圖片進行升採樣,每一步圖像的清晰度都有提升。
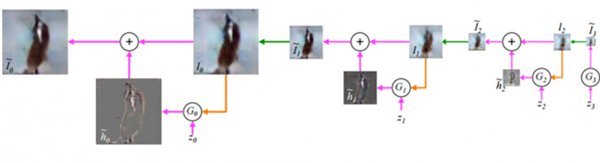
▲拉普拉斯金字塔結構圖像生成示意
這產生了一個新概念:有條件生成對抗網絡(conditional GAN,CGAN),指的是它有多個輸入:低解析度圖片和噪音矢量。該研究生成的高質量圖片,在40%的情況下被真人裁判當做真實圖像。
對該研究的意義,李嫣然評論道:它將GAN的學習過程變成了「序列式」的——不要讓GAN一次學完全部的數據,而是讓GAN一步步完成這個學習過程。
3.利用GANs把文字轉化為圖像
把文字轉化為圖像,比起把圖像轉為文字(讓AI用文字概括、描述圖像)要難得多。一方面是近乎無限的像素排列方式;另一方面,目前沒人知道如何把它分解,比如像(圖像轉為文字任務中)預測下一個詞那樣。
2016年6月,論文《Generative Adversarial Text to Image Synthesis》(「GANs文字到圖像的合成」)問世。它介紹了如何通過GANs進行從文字到圖像的轉化。比方說,若神經網絡的輸入是「粉色花瓣的花」,輸出就會是一個包含了這些要素的圖像。該任務包含兩個部分:1.利用自然語言處理來理解輸入中的描述。2.生成網絡輸出一個準確、自然的圖像,對文字進行表達。
為實現這些目標,生成器和判別器都使用了文字編碼技術:通過循環文字編碼器(recurrent text encoder)生成的文字屬性,來作為條件對GAN進行訓練。這使得GAN能夠在輸入的文字描述和輸出圖像之間建立相關性聯繫。
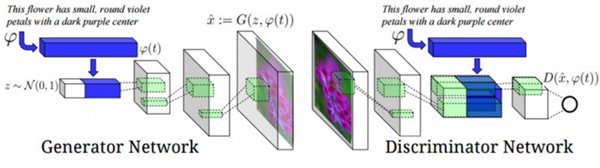
▲原理示意
該任務中,GAN其實完成了兩件任務:1.生成自然、說得過去的圖像;2.圖像必須與文字描述有相關性。

利用GAN, GAN-CLS, GAN-INT,GAN-INT-CLS生成的結果示意。GT是真實圖像,從左到右三組圖像的任務分別是:1.全黑色的鳥,粗圓的鳥嘴;2.黃胸、棕冠、黑眉的小鳥;3.藍冠、藍羽、黑頰的超小鳥,嘴小、踝骨小、爪小。
4. GANs應用於超解析度(Super Resolution)
這是推特 Cortex研究團隊進行的一項研究,在今年9月發表。它的主要貢獻是開發出全新的損失函數(loss function),使得GANs能對大幅降採樣後的圖像,恢復它的生動紋理和小顆粒細節。
對於不熟悉超解析度的讀者,它是一個能把低解析度圖像重建為高清圖像的技術。在機器學習中,實現超解析度需要用成對樣本對系統進行訓練:一個是原始高清圖像,一個是降採樣後的低解析度圖像。本研究中,低分圖像被作為輸入餵給生成器,它重建出高解析度圖像。然後,重建圖片和原始圖片被一起交給判別器,來判斷哪一幅是原始圖像。
該研究中的損失函數可分為兩個部分:對抗損失(adversarial loss )和內容損失(content loss)。在較高層面上,對抗損失使圖像看起來更自然;內容損失則保證重建圖像與低解析度原始圖像有相似的特點。其中,對抗損失和傳統的GANs應用類似,創新的是內容損失。該研究中的內容損失,可被看作為重建的高解析度圖像和原始高分圖像之間特徵圖(feature map)的歐式距離(Euclidean distance)損失。而GAN的損失函數是對抗損失和內容損失的加權和。

▲左欄是原始圖像,右三欄是GANs重建的高分圖像。
以上是GANs 2014-2016發展期間的主要里程碑。但讀者們注意,2016年以來,GANs的研究應用層出不窮。以上只是最具代表性的幾個,不代表其他GANs研究就沒有價值。
值得一說的是,今年6月一篇關於深度卷積GANs(Deep Convolutional Generative Adversarial Networks,DCGAN)的論文在業內引發強烈反響:《使用深度卷積GANs進行無監督表征學習》。研究人員們發現,用大規模資料庫訓練出的GANs 能學習一整套層級的特徵(a hierarchy of features),並具有比其他無監督學習模型更好的效果。而此前使用CNN訓練GANs的嘗試大多以失敗告終。當研究人員修改架構創造出DCGAN,他們能夠看到神經網絡在每一層級學習到的過濾器 。Yan Lecun評論道,這打開了GANs的「黑箱」。
最後,我們來看看在大神Yan Lecun眼裡,GANs為什麼這麼重要:
「它為創建無監督學習模型提供了強有力的算法框架,有望幫助我們為AI加入常識(common sense)。我們認為,沿著這條路走下去,有不小的成功機會能開發出更智慧的AI。」
轉貼自: 壹讀

留下你的回應
以訪客張貼回應