
摘要: 本文從大數據的發展現狀分析入手,討論了大數據對傳統經濟學的挑戰,首次提出大數據經濟學的概念。認為大數據經濟學包括大數據計量經濟學、大數據統計學和大數據領域經濟學,並分析了大數據經濟學與信息經濟學、信息...
本文從大數據的發展現狀分析入手,討論了大數據對傳統經濟學的挑戰,首次提出大數據經濟學的概念。認為大數據經濟學包括大數據計量經濟學、大數據統計學和大數據領域經濟學,並分析了大數據經濟學與信息經濟學、信息技術等相關學科的關係,最後對大數據經濟學發展前景進行了展望,認為大數據經濟學不僅將理論科學、實驗科學、複雜現像模擬統一在一起,而且將自然科學和社會科學統一在一起,將理論研究與實踐應用實時地統一在一起,大數據經濟學具有“智能經濟學”的特點。
1、引言
2012 年,Twitter上每天發布超過4億條微博,Facebook上每天更新的照片超過1000萬張,Farecast公司用將近10萬億條價格記錄來預測機票價格,準確率高達75%,採用該系統購票,平均每張機票可節省50美元。 Gartner預測未來5年全球大數據將會增加8倍,其中80%是非結構化數據。 2013年世界上存儲的數據將達到1.2ZB(1ZB=1024EB,1EB=1024PB,1PB=1024TB,1TB=1024GB),如果將這些數據刻錄到CDR只讀光盤上,並堆起來,其高度將是地球到月球距離的5倍。 2011年,麥肯錫公司對全世界大數據的分佈作了一個研究和統計,中國2010年新增的數據量約為250PB,而歐洲約為2000PB,美國約為3500PB,大數據已經深深地充斥了人類經濟社會的許多角落。
著名未來學家阿爾文·托夫勒(1980)[1]很早就在其經典著作《第三次浪潮》中,將大數據熱情地讚譽為“第三次浪潮的華彩樂章”,但是大數據成為高頻詞是最近一兩年的事情。隨著社交網絡、物聯網、雲計算的興起,數據規模越來越大,2011年5月,全球知名諮詢公司麥肯錫(Mckinsey and Company)發布了《大數據:創新、競爭和生產力的下一個前沿領域》[2]報告,標誌著“大數據”時代的到來,指出“數據已經滲透到每一個行業和業務職能領域,逐漸成為重要的生產因素;而人們對於海量數據的運用將預示著新一波生產率增長和消費者盈餘浪潮的到來”。 2012年世界經濟論壇發布了《大數據、大影響》[3]的報告,從金融服務、健康、教育、農業、醫療等多個領域闡述了大數據給世界經濟社會發展帶來的機會。 2012年3月,奧巴馬政府發布《大數據研究和發展倡議》[4],投資2.5億美元,正式啟動大數據發展計劃,計劃在科學研究、環境、生物醫學等領域尋求突破。據Gartner公司2012年8月發布的技術發展生命週期[5]趨勢圖(圖1),大數據不到兩年時間內成為新技術發展的熱點。一時間大數據蜂擁襲來,那麼什麼是大數據?大數據對傳統經濟學會帶來哪些衝擊?傳統經濟學應該如何面對大數據帶來的挑戰?
對於什麼是大數據,目前業界並沒有公認的說法。 Dumbill(2012)[6]採用IBM公司的觀點,認為大數據具有“3V”特點,即規模性(Volume)、多樣性(Variety)、實時性(Velocity)。以IDC 為代表的業界認為大數據具備“4V”特點,即在3V的基礎上增加價值性(value)。 NetApp公司[7]認為大數據應包括A、B、C 三大要素,即分析(Analytic)、帶寬(Bandwidth)和內容(Content)。所謂大分析(BigAnalytics),指通過對大數據進行實時分析後帶來新的業務模式,幫助用戶獲得洞見,從而更好進行客戶服務;高帶寬(Big Bandwidth)指快速有效地消化和處理大數據;大內容(Big Content)一方面指大數據包括結構化、半結構化數據與非機構化數據,另一方面則是指對數據的存儲擴展要求極高,能輕鬆實現數據的恢復、備份、複製與安全管理。 Gartner認為,大數據需要新的處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。
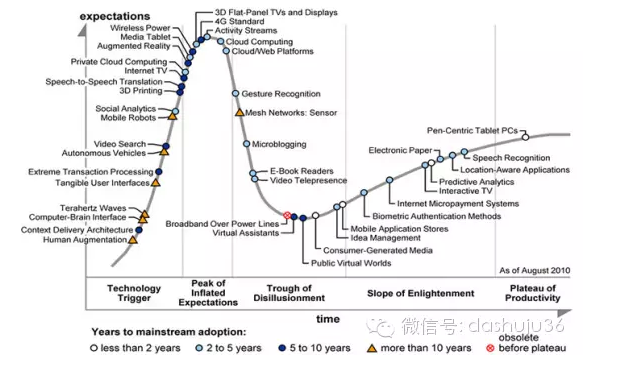
圖1 Gartner新技術生命週期
大數據是工業傳感器、互聯網、移動數碼等固定和移動設備產生的結構化數據、半結構化數據與非結構化數據的總和,大數據重在實時的處理與應用,以獲得所需要的信息和知識,從而實現商業價值以及為公共管理服務,數據挖掘和人工智能等應用工具在大數據處理中發揮著重要作用,現代信息技術是大數據賴以存在和發展的重要支撐力量。
2、大數據給經濟學帶來的影響
Victor(2012) [8]在其最新著作《大數據時代——生活、工作與思維的大變革》中指出,大數據時代,思維方式要發生3個變革:第一,要分析與事物相關的所有數據,而不是依靠分析少量數據樣本;要總體,不要樣本。第二,要樂於接受數據的紛繁複雜,而不再追求精確性。第三,不再探求難以捉摸的因果關係,應該更加註重相關關係。楊華磊(2013)[9]分析了高頻數據對傳統經濟學研究範式的衝擊,出現了“非主流經濟學就是致力研究異常現象的經濟學”,當然高頻數據與大數據不是一回事,兩者之間存在交集。那麼,大數據給經濟學帶來了哪些影響呢?
2.1大數據研究對像變成了總體
傳統經濟學研究中,由於蒐集數據的條件所限,人們往往對數據進行抽樣,用少量樣本來進行研究,這一傳統一直延續至今,並且成為經濟學研究的主流做法,但是抽樣的質量對研究結果影響很大,比如公眾對政府統計部門公佈的物價指數和基尼係數引發的懷疑。在大數據時代,很多場合下已經無需進行針對樣本的研究,直接將總體作為研究對象,從而很大程度上改變了數據來源方式,對數據的處理也產生了深遠的影響。
2.2大數據不需要基於假設檢驗的研究
傳統的經濟學研究,往往根據研究內容提出數個假設,然後再採用數學模型基於統計檢驗來驗證假設。但在大數據時代,由於有足夠的變量、足夠的數據,可以採用人工智能來進行數據挖掘和知識發現,得到的結論是成百上千的,和傳統經濟學研究需要驗證假設的數量永遠不是一個數量級。在大數據時代,如果繼續採用傳統的假設檢驗方法進行研究,永遠是不充分的、不完備的、無法滿足需要的。大數據時代重在對數據處理的多樣化結果進行分析,可以是基於經濟學的,也可以是基於應用的,從而輔助人們決策。
此外,由於變量的完備性要求使得傳統的基於假設驗證的研究有時變得十分尷尬。比如,研究研發投入對企業績效的影響,需要考慮的不僅僅是研發投入,還要考慮企業資本結構、競爭水平、人員素質、行業特點、管理能力等諸多因素,研究者重點關注的是研發投入的彈性係數,但卻得到了其他所有數十個變量的彈性係數,從而使研究重心不容易掌握。
2.3大數據使得因果關係變得不太重要
傳統經濟學是一門解釋科學,重在對經濟現象的解釋,了解他們的因果關係,但在大數據時代,這樣做是遠遠不夠的,大數據甚至可以發現事物發展潛在的規律,以供經濟學家解釋,具有一定的“智能性”,某種程度上超越了經濟學研究的因果關係。
大數據並沒有改變因果關係,但是使傳統經濟學的因果關係變得不太重要。比如經濟學家在預測房價時,無非是根據住房價格變化的影響因素來進行分析,比如經濟發展水平、人均收入、土地價格、宏觀房產政策、地點等因素。但谷歌預測房價時,根據住房搜索查詢量變化進行預測,結果比不動產經濟學家的預測更為準確及時。 IBM日本公司,通過檢索關鍵詞“新訂單”、“僱員”、“生產”等來預測採購經理人指數,僅用6小時就得出結果,並且和專業的採購人指數分析師們計算的結果基本一致。大數據並沒有改變因果關係,但使因果關係變得意義不大,很多時候因果關係成為“正確的廢話”。
2.4傳統的因果關係有時無法驗證
弄清事物之間的內在聯繫和作用機制,一直是傳統經濟學研究的核心。但有時因果關係是沒有辦法驗證的。比如新產品上市,人們往往傾向於購買新產品,這樣對舊產品的需求會下降,那麼舊產品價格應該立即回落,這是其一。從另外一個角度,如果大家都認識到這一點,就會貪便宜購買舊產品,短期內會造成舊產品供不應求, 反而導致舊產品漲價。究竟是漲是跌,要看這兩種因素誰弱誰強,採用傳統經濟學研究方法是難以驗證這兩種效應的,只能驗證兩種效應作用的綜合結果。
實際情況是,在大數據時代,西雅圖Decide.comg公司分析了近400萬商品的超過250億條價格信息,發現新產品上市時,短期內舊產品價格是上漲的,過一段時間才逐步回落。採用大數據,既可以知道多少人購買舊產品,也能知道多少人購買新產品,以及舊產品價格變化的規律。在這種情況下,我們知道所有的因果關係,卻難以檢驗,並且沒有意義,知道結果更重要。
2.5傳統經濟學研究具有滯後性
傳統經濟學對於新生事物是不敏感的,必須等事情發生並且成長到一定規模以後才能蒐集到足夠數據進行相關研究。在大數據時代,可以通過海量數據對經濟行為進行分析,一旦有新情況、新動態立即予以關注,從而實現對新生事物的早期干預和分析,因此具有前瞻性。大數據本身就具有智能,可以輔助經濟學發現知識。
2.6大數據對基於統計檢驗的計量經濟學衝擊很大
建立在回歸和統計檢驗基礎上的計量經濟學以其嚴謹的邏輯成為經濟學研究的重要方法論,迄今為止,諾貝爾經濟學獎獲得者有近半數是計量經濟學家,但大數據動搖了這一根基,比如採用普通回歸研究自變量X於因變量Y的關係,對於X回歸係數採用t檢驗,一般認為相伴概率小於0.05(特殊情況可以放大到0.1)就說明兩變量相關。其實在這種情況下,犯兩變量不相關錯誤的可能性是5%,以CNNIC發布的《第31次中國互聯網絡發展狀況統計報告》[10]為例,2012年底我國網民數量達5.64億人,假設我們研究網民平均受教育年限(X)與上網時長(Y)的關係,5%就是2820萬人,此時我們還能漠視這5%的錯誤嗎?同樣,如果t檢驗的相伴概率為0.95,那麼很明顯說明平均受教育年限與上網時長不相關,但同樣會犯錯誤,即有5%的可能性平均受教育年限(X)與上網時長(Y )是相關的,會涉及2820萬網民,這同樣是不能忽視的。
2.7大數據對經濟學建模提出挑戰
傳統的經濟學研究,往往採用1個或少數幾個數學模型來進行研究,但任何模型都各有長處,也各有其局限,沒有包治百病萬能的數學模型。比如動態面板容易使投入變量的彈性係數估計變小,空間面板容易出現空間矩陣設置方法不當導致結果偏誤,面板變係數模型難以和空間面板結合使用,面板聯立方程模型對方程形式的要求極高,面板向量自回歸模型難以和空間面板融合等等。在研究同一問題時,可用模型其實較多,有沒有最佳模型呢?這恐怕是個無解的問題。實際情況是,迄今為止傳統經濟學研究得出的結論,至多只能說明採用甲模型的結論,並不具有普適性,換個乙模型結論可能立即就變了,其實研究結論是脆弱的。
此外,在研究同一個問題時,即使採用同一模型,由於模型的變量選擇、估計的方法、參數設置、滯後期選擇等不同,也會導致估計結果相差很大。
在大數據時代,借助雲計算和分佈式處理等現代信息技術,往往可以採用成百上千的模型來進行研究。 Google公司在預測2009年美國甲型H1N1流感爆發時間時,把5000萬條美國人常用的檢索詞條和美國疾控中心2003~2008年期間季節性流感傳播數據進行比較,希望通過搜索記錄判斷這些人是否得了流感,先後共採用了4.5億個不同的數學模型,預測結果和官方數據的一致率高達97%,但比官方節省了兩週時間,從而為政府採取相關措施贏得了寶貴的時間。
在傳統經濟學研究中,由於研究對象錯綜複雜,直接影響與間接影響因素眾多,變量的完備性被認為是不可能的事情,往往只能選取少數變量來進行研究,達到一個相對滿意的結果。在大數據時代,我們可以獲取越來越多的變量,從而使遺失變量的可能性降到最低,這樣在研究中由原來的數個變量可能會變成數十個甚至成百上千的變量,在這樣的情況下,對原有的建模技術就帶來了巨大挑戰,對計量經濟學的發展將會產生深遠影響。
2.8大數據給經濟學研究工具和手段發生變化
傳統經濟學研究,一個團隊,數台電腦,幾個軟件就能進行像樣的研究,很少有運算需要動用大中型服務器的,但在大數據時代,經濟學研究發生了巨大的變化,在人員組成上,不光要有經濟學家和領域專家,還要有大數據維護專家、大數據建模專家;在計算工具上,需要廣泛借助雲計算,幾台電腦根本解決不了問題;從合作關係上,需要廣泛與政府、大數據擁有者、雲計算服務商等合作,不然難以進行研究。大數據時代,經濟學研究必須依靠跨學科團隊,傳統的少數幾個學者就能進行研究的模式已經難以為繼。
2.9大數據徹底改變了傳統的統計調查方式
大數據徹底改變了傳統的統計調查方式,比如對於經濟指數、物價指數的計算,完全可以採用全新的模式,徹底摒棄傳統方式。對於統計學中的異常點,以往的處理方式往往是丟棄,或者是平滑,在大數據時代,由於樣本眾多,異常點成為寶貴的資源和研究對象廣受重視。傳統的統計數據是經過加工後的結構化的數據,在大數據時代,人們更加重視原始數據和非結構化數據,因為如果統計數據已經經過加工,那就變成了二手數據,如果一手數據加工過程出現問題必然導致後續處理出現誤差。此外,大數據還使間隔時間較短的高頻數據研究成為可能。
3、大數據經濟學
3.1大數據經濟學的定義與研究內容
考慮到大數據給傳統經濟學帶來的巨大衝擊和影響,迫切需要對此進行研究,斯坦福大學的教授、沃爾瑪全球電子商務的高級副總裁、WalmartLabs的共同創立者AnandRajaraman(2012)[11]發明了一個新詞Econinformatics,指將計算機科學和信息技術應用於經濟學領域,特別指應用於大數據的經濟分析。由於該詞和Information Economics的意義相近,翻譯成中文後更容易混淆,加上其和Ecoinformatics(生態)相近,因此並不是一個好的名詞。本文提出大數據經濟學(Big Data Economics或Economics of BigData),給出如下定義:
大數據經濟學是在經濟學研究和應用中採用大數據並且採用大數據思想對傳統經濟學進行深化的新興交叉學科。大數據經濟學不僅要研究如何建模、管理和應用大數據,而且要深入研究傳統經濟學如何應對大數據帶來的挑戰並進行改良,大數據經濟學需要經濟學家、領域專家和信息技術專家等密切合作,對人文社科與自然科學的跨學科研究提出了更高的要求,並且對整個經濟學、社會學、公共管理等將帶來革命性變革。大數據經濟學的研究內容包括:
第一,大數據計量經濟學(Big Data Econometrics)。這是和傳統計量經濟學對應的一個學科,也是大數據經濟學下面的子學科。在大數據背景下,經濟學建模與分析方法與傳統計量經濟學完全不同,迫切需要採用全新的思路和方法進行研究。對信息技術專家們而言,大數據經濟學僅僅是算法和建模問題,但是如果沒有經濟學理論指導,沒有經濟學家的思維,必然會導致研究方向的迷失。一些大數據領域的學者認為“要相關,不要因果”,這是非常要不得的,傳統經濟學理論至今仍然到處閃爍著智慧的光芒, 對經濟現象的深入見解時刻發揮著重要的作用,所以大數據背景下的經濟學分析不能主要靠信息技術的建模專家來進行,必須繼續依靠大數據計量經濟學家。
第二,大數據統計學(Big Data Statistics)。如前所述,大數據給統計學帶來的挑戰是革命性的,在某些領域,傳統統計學所採用的抽樣調查方式必將徹底淘汰。此外,傳統統計學所要求的精確數據與數據加工方式可能是畫蛇添足甚至敗筆之舉,人們更加重視對一手數據而不是經過加工過的二手統計數據進行分析。大數據時代,人們更加關注原始數據、關注半結構化甚至非結構化數據,瀏覽記錄、查詢關鍵詞、微薄文字、照片等等都是寶貴的數據資源。在大數據時代,傳統統計學也必須進行變革,對數據儲存手段、處理設備、處理方法都提出了新的要求。
第 三,大數據領域經濟學。包括大數據生態經濟學、大數據環境經濟學、大數據金融學、大數據城市經濟學、大數據工業經濟學、大數據農業經濟學、大數據交通經濟學、大數據建築經濟學、大數據商業經濟學、大數據信息經濟學、大數據人口經濟學等學科,借用大數據的思想和技術來進行各應用經濟領域的研究。
在以上大數據經濟學的各學科中,大數據統計學是基礎,大數據計量經濟學是研究方法,而大數據領域經濟學是具體的運用,他們之間存在著密切的共生關係。
大數據由於是基於總體的,很大程度上解決了傳統宏觀經濟學與微觀經濟學缺乏較強邏輯聯繫的問題,此外大數據對傳統計量經濟學帶來的一個有益之處就是,結構化的大數據更加接近正態分佈,這樣就降低了小樣本假設檢驗失效問題。
3.2大數據經濟學與傳統經濟學的關係
大數據經濟學剛剛提出,現在討論其與其他學科的關係也許為時尚早。大數據經濟學與與傳統經濟學是一種互補共存關係,在大數據經濟學誕生之初,由於大數據經濟學理論和技術尚不成熟,雖然大數據經濟學發展很快,但仍然以傳統經濟學為主,隨著大數據經濟學的發展,兩者會達到某種均衡。畢竟,大數據不能解決所有的經濟學問題,一些研究仍然無法獲得大數據,需要採用傳統經濟學解決的問題留待傳統經濟學解決,需要大數據經濟學解決的問題由大數據經濟學解決。
3.3大數據經濟學與信息經濟學的關係
大數據是現代信息技術高速發展的產物,因此必須研究大數據經濟學與信息經濟學的關係。傳統信息經濟學(Information Economics)包括兩個部分:宏觀信息經濟學與微觀信息經濟學,嚴格意義上講,這兩者並沒有必然的關係。 Machlup(1962)[12]和Porat(1977)[13]是宏觀信息經濟學的創始人,又稱為情報經濟學、信息產業經濟學,主要從產業經濟學角度研究信息這一特殊商品的生產、流通、 利用以及經濟效益的一門新興學科,研究視角集中在信息化與產業經濟學,是經濟學的重要分支。
Stigler(1961) [14]和Arrow(1972)[15]是微觀信息經濟學的創始人,又稱為理論信息經濟學,研究不對稱信息理論、信息商品的分析、信息成本和價格、信息市場分析、信息搜尋理論等,提出用不完全信息理論來修正傳統的市場模型中信息完全對稱的假設,又稱契約理論或機制設計理論。
大數據產業自身發展的經濟學問題仍然屬於信息經濟學的範疇,不屬於大數據經濟學。隨著大數據的迅猛發展,據世界經濟論壇預測,大數據會為全球帶來440 萬個IT 崗位,其中190 萬個在美國,另外每一個大數據的崗位會催生3 個非IT 就業崗位,也就是說未來會推動美國產生600 萬個就業崗位,這類問題就是信息經濟學的研究範疇。
3.4大數據經濟學與信息技術及其他相關學科的關係
毋庸置疑,大數據經濟學離不開現代信息技術,是現代信息技術發展到大規模計算與存儲階段的必然結果,甚至在信息技術專家眼裡,大數據僅僅是一種技術。但是大數據經濟學更是一種思想,只不過現代信息技術使這種思想成為可能。大數據經濟學必須以現代信息技術為基石,重在研究其在經濟學領域中的應用,因此大數據經濟學是一個學科跨度很大的學科,包括經濟學、管理工程、統計學、信息技術、情報學、心理學等相關學科。
4、大數據經濟學發展展望
本文首次提出大數據經濟學的概念,大數據經濟學將是21世紀經濟學的重大進展之一。它是隨著大數據在人類經濟社會中的應用而產生的,目前尚處於萌芽階段,其實踐遠遠超越理論,可以預見的是,不久的將來是大數據經濟學的理論建構和高速發展期,借助高度發達的現代信息技術,大數據經濟學理論可以隨時得到檢驗和修正,這樣一開始大數據經濟學就處在一個很高的研究和應用水平上,其發展速度遠遠高於其他任何新興學科,這也是現代信息技術對新興學科的重要貢獻之一。
從學科分類上,目前的經濟學包括理論經濟學與應用經濟學兩個一級學科,可以預計的是,隨著大數據經濟學的日益發展與成熟,大數據經濟學將成為和理論經濟學與應用經濟學並列的一級學科,是經濟學一級學科中的“小弟弟”。
圖靈獎得主Jim Gray 2007年在美國國家科學研究委員會發表演講,指出科學研究共經歷了4個階段:數千年前,人類註重採用實驗科學來描述自然現象;幾百年前,人類註重理論科學;幾十年前,人類轉向計算科學,模擬複雜現象;而今天,人類進入數據探索階段,將理論科學、實驗科學、複雜現像模擬趨於統一。 Jim Gray的結論主要針對自然科學,對大數據經濟學而言,不僅是將理論科學、實驗科學、複雜現像模擬統一在一起,而且將自然科學和社會科學統一在一起,將理論研究與實踐應用實時地統一在一起,大數據經濟學將是智能經濟學。
資料來源:煉數成金


留下你的回應
以訪客張貼回應