
摘要: 機器學習與人工智慧變得越來越熱。大數據原本在工業界中就已經炙手可熱,而基於大數據的機器學習則更加流行,因為其通過對數據的計算,可以實現數據預測、為公司提供決策依據。
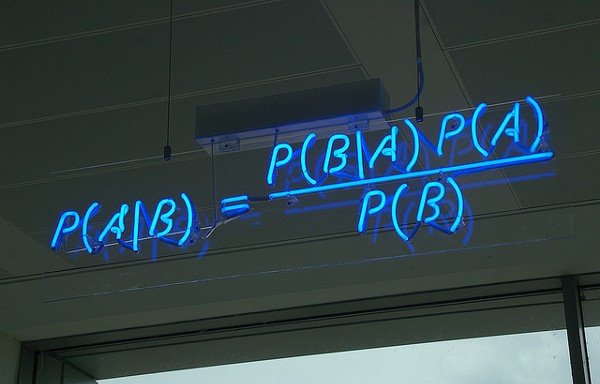
James Le 在 KDnuggets 上發布了一篇文章,介紹了他是如何入門機器學習的。
如果你想學機器學習,那怎麼入門呢?對於我來說,我是這樣開始我的機器學習的,首先,我選修了一門人工智能課程。教我課程的老師是Technical University of Denmark的大學教授,他的研究方向就是邏輯與人工智慧。我們用的教材是人工智慧的經典教材: Peter Norvig's Artificial Intelligence — A Modern Approach。這本書主要講了智能主體、對抗搜索、機率論、多智能系統、AI哲學等等。這門課程我上了三個學期,最後我做了一個簡單的基於搜索的智能系統,這個系統可以完成虛擬環境下的傳輸任務。
通過這門課程我學到了很多知識,在將來我還要繼續學習。最近幾周,我有幸在舊金山的舉辦的機器學習大會上與眾多機器學習大神交談,我和他們聊了很多關於深度學習、神經網絡、數據結構的內容。此外,我還在網上選修了一門機器學習入門課程,正巧剛剛修完。在接下來內容中,我將和大家分享我在這門課程中所學到的機器學習常用算法。
機器學習算法分為三類:有監督學習、無監督學習、增強學習。有監督學習需要標識數據(用於訓練,即有正例又有負例),無監督學習不需要標識數據,增強學習介於兩者之間(有部分標識數據)。下面我將向大家具體介紹機器學習中10大算法(只介紹有監督、無監督兩類,暫不介紹增強學習)。
一、監督式學習
算法一:決策樹
決策樹是一種樹形結構,為人們提供決策依據,決策樹可以用來回答yes和no問題,它通過樹形結構將各種情況組合都表示出來,每個分支表示一次選擇(選擇yes還是no),直到所有選擇都進行完畢,最終給出正確答案。
算法二:貝氏分類
樸素貝葉斯分類器基於貝葉斯理論及其假設(即特徵之間是獨立的,是不相互影響的)
P(A|B) 是後驗機率, P(B|A) 是似然,P(A)為先驗機率,P(B) 為我們要預測的值。
具體應用有:垃圾郵件檢測、文章分類、情感分類、人臉識別等。
算法三:最小平方法
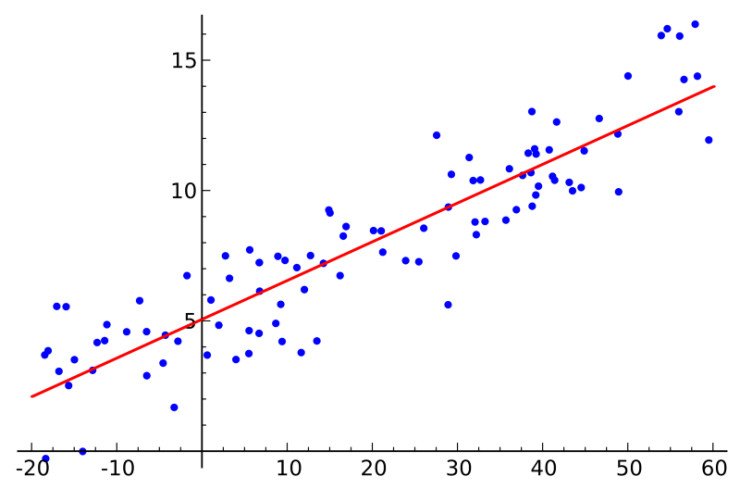
如果你對統計學有所了解,那麼你必定聽說過線性回歸。最小均方就是用來求線性回歸的。如下圖所示,平面內會有一系列點,然後我們求取一條線,使得這條線儘可能擬合這些點分布,這就是線性回歸。這條線有多種找法,最小二乘法就是其中一種。最小二乘法其原理如下,找到一條線使得平面內的所有點到這條線的歐式距離和最小。這條線就是我們要求取得線。
線性指的是用一條線對數據進行擬合,距離代表的是數據誤差,最小平方法可以看做是誤差最小化。
算法四:邏輯回歸
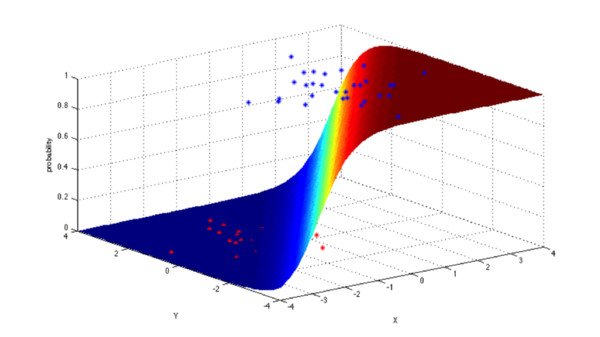
邏輯回歸模型是一個二分類模型,它選取不同的特徵與權重來對樣本進行機率分類,用一各log函數計算樣本屬於某一類的機率。即一個樣本會有一定的機率屬於一個類,會有一定的機率屬於另一類,機率大的類即為樣本所屬類。
具體應用有:信用評級、營銷活動成功機率、產品銷售預測、某天是否將會地震發生。
算法五:支持向量機(SVM)
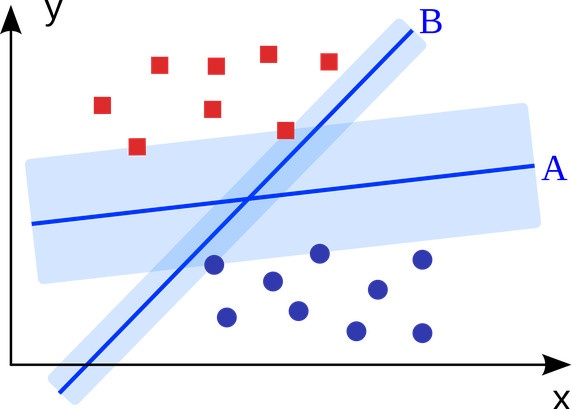
支持向量機是一個二分類算法,它可以在N維空間找到一個(N-1)維的超平面,這個超平面可以將這些點分為兩類。也就是說,平面內如果存在線性可分的兩類點,SVM可以找到一條最優的直線將這些點分開。SVM應用範圍很廣。
具體應用有:廣告展示、性別檢測、大規模圖像識別等。
算法六:集成學習
集成學習就是將很多分類器集成在一起,每個分類器有不同的權重,將這些分類器的分類結果合併在一起,作為最終的分類結果。最初集成方法為貝葉斯決策,現在多採用error-correcting output coding, bagging, and boosting等方法進行集成。
那麼為什集成分類器要比單個分類器效果好呢?
1.偏差均勻化:如果你將民主黨與共和黨的投票數算一下均值,可定會得到你原先沒有發現的結果,集成學習與這個也類似,它可以學到其它任何一種方式都學不到的東西。
2.減少方差:總體的結果要比單一模型的結果好,因為其從多個角度考慮問題。類似於股票市場,綜合考慮多隻股票可以要比只考慮一隻股票好,這就是為什麼多數據比少數據效果好原因,因為其考慮的因素更多。
3.不容易過擬合。如果的一個模型不過擬合,那麼綜合考慮多種因素的多模型就更不容易過擬合了。
二、非監督式學習
算法七:聚類算法
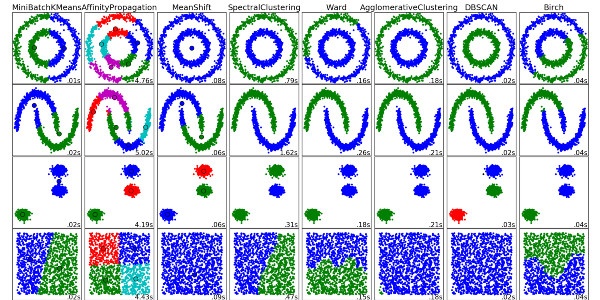
聚類算法就是將一堆數據進行處理,根據它們的相似性對數據進行聚類。
聚類算法有很多種,具體如下:中心聚類、關聯聚類、密度聚類、機率聚類、降維、神經網絡/深度學習。
算法八:主成分分析(PCA)
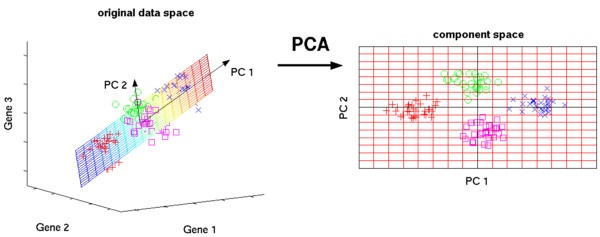
主成分分析是利用正交變換將一些列可能相關數據轉換為線性無關數據,從而找到主成分。
PCA主要用於簡單學習與可視化中數據壓縮、簡化。但是PCA有一定的局限性,它需要你擁有特定領域的相關知識。對噪音比較多的數據並不適用。
算法九:SVD矩陣分解
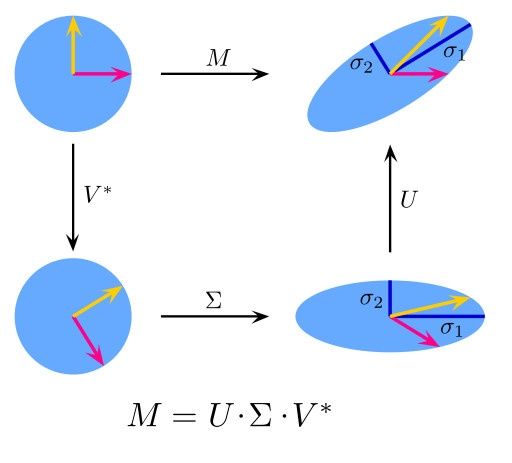
SVD矩陣是一個複雜的實復負數矩陣,給定一個m 行、n列的矩陣M,那麼M矩陣可以分解為M = UΣV。U和V是酉矩陣,Σ為對角陣。
PCA實際上就是一個簡化版本的SVD分解。在計算機視覺領域,第一個臉部識別算法就是基於PCA與SVD的,用特徵對臉部進行特徵表示,然後降維、最後進行面部匹配。儘管現在面部識別方法複雜,但是基本原理還是類似的。
算法十:獨立成分分析(ICA)
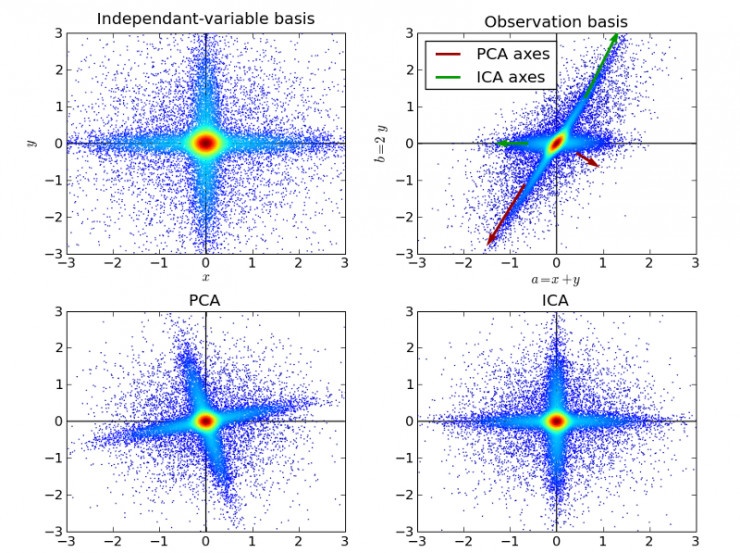
ICA是一門統計技術,用於發現存在於隨機變量下的隱性因素。ICA為給觀測數據定義了一個生成模型。在這個模型中,其認為數據變量是由隱性變量,經一個混合系統線性混合而成,這個混合系統未知。並且假設潛在因素屬於非高斯分布、並且相互獨立,稱之為可觀測數據的獨立成分。
ICA與PCA相關,但它在發現潛在因素方面效果良好。它可以應用在數字圖像、檔文資料庫、經濟指標、心裡測量等。
轉貼自: 壹讀

留下你的回應
以訪客張貼回應